Archive for category coding
Determining SQL datatypes from wide CSV data
Posted by sqlpete in coding, architecture on May 1, 2024
Thirty second summary
When importing a CSV file, SQL Server’s Import/Export wizard isn’t great at working out the correct column datatypes for the new table — which is especially painful when the CSV is wide (has many columns) — so I wrote some SQL code to get round the issue.

Everyone working in BI / data science has to move data around between apps all the time, and it’s a constant surprise to me how this is still somewhat of a pain. In particular, getting CSV data into a SQL Server table with the datatypes you require is a very hit-and-miss affair. The GUI tools SSMS provides you with aren’t really up to the task, especially when the CSV files are very wide.
In this post, I’ll demonstrate how I tackled this problem.
Motivation
Warning: This section is quite waffle-y, please feel free to skip
In 2018, the consumer lender Home Credit ran a competition on the data science community site kaggle, to see who could come up with the best predictive model for a given data set: “The objective of this competition is to use historical loan application data to predict whether or not an applicant will be able to repay a loan.” All the details are given here.
The competition closed 3 months later with a whopping 7180 entries! The winning team, comprising 6 senior data scientists, won $35,000. In discussion about their winning code, they wrote: “… for this kind of competition and this kind of problem, feature engineering and feature selection are still the most important step.”
Feature engineering means manipulating the data you have to generate more predictive variables, and it’s hands down my favourite part of building models — it’s basically playing with data, using as much creativity as you can muster. Some examples from my own work:
- Parsing business names and addresses to tease out company-level data that didn’t otherwise exist
- Sub-models of ‘customer enquiry’ data to add a much richer ‘search score’ (how ‘urgent’ the customer’s requirement for the money is)
- Combining socio-demographic statuses to paint clearer pictures of applicants
- Augmenting residential statuses with given electoral roll data to better explain a customer’s living situation
- Generating huge numbers of ratios concerned with debt, income, expenses, and all aspects of affordability
It’s then straightforward to weed out those variables that aren’t predictive (part of feature selection).
Having some time on my hands, I decided to play with this dataset, and see how close I could get to the performance of the winning teams. I’m not completely daft — I’m not expecting much, some (all?) of the winning team are PhD ‘Heads of Data Science’ at huge companies. Still, it seems like a fun thing to try. Stay tuned for a future post on my efforts!

SQL Is Best
Now, because I’ve used it, day in and day out, for so many years, I’m accustomed to getting to grips with my data, trying to really understand it, in SQL Server — not Python, or even R. So, I want to get the data into SQL Server first. And here’s the stumbling block: we have multiple CSV files, some of them with over a hundred columns.
Anyone who uses SSMS/SQL Server knows that the Import Wizard is… let’s be polite, ‘lacking in features’. Or less polite, bloody annoying. For me, a far more flexible and fruitful approach is to import all the data as text ([N]VARCHAR), and do all our transformations using pure SQL.
The first CSV I’m looking at (application_train.csv from the competition dataset) has 122 columns, and while I could work out the datatypes manually, it’s more fun to write code to do it for me!
My solution
Let’s get the data into SQL Server as text.
Getting the raw data into SQL Server: BULK INSERT
I copied/pivoted the column names from the first row of the CSV, and created a SQL table app_train_raw that consisted of one integer column (the unique customer ID), and 121 VARCHAR(50) columns. I then inserted the data using BULK INSERT:
BULK INSERT dbo.app_train_raw FROM '...\application_train.csv' WITH ( FORMAT = 'CSV' ,FIRSTROW = 2-- i.e. skip header row,ROWTERMINATOR = '0x0a'-- character 10, Line Feed)
It took a few seconds to insert the 307,511 rows, a total of 37,516,342 data points.
Warning: BULK INSERT doesn’t give good error messages. I kept getting an error about ‘conversion error (truncation)’, so spent ages messing with text encodings, trying to find rogue characters in the CSV — when in fact, I’d miscounted the number of columns!
The code
I’m not going to present the entirety of my code, because (a) this post would be too long, (b) it’s just ‘glue’ code. I maintain a config table with one row per column from the original CSV, and whether I’ve already determined the data type, or created a lookup. Also, I’m doing this all iteratively: identifying the types of columns as I go along, then re-running sections of code, ignoring those with known types.
From here on, I’ll post only the most relevant bits.
Initial categorisation
In my post Aggregating all the categorical data in a table, there’s code I wrote to, well, aggregate all the categorical data from a table (in order to calculate the Population Stability Index for each variable in the models).
We can use the exact same code here, and run it over all 121 VARCHAR(50) columns. You might think it would take a long time to GROUP all these columns, but it took just 19 seconds on my old PC. We’re left with the global temp table ##Results, containing 388,218 rows: each row is a distinct variable/value pair, we’re not interested in duplicate values.
Analysing the categories
The first thing we can do is look for obvious candidates for columns that we can ‘normalise out’ as lookup tables:
SELECT [var], COUNT(1)
FROM ##Results
GROUP BY [var]
HAVING COUNT(1) < 30
This led me to 13 columns (mostly ending _STATUS, _TYPE) that I turned in to lookup tables. This didn’t take long, and could easily be automated.
Next, let’s gather some information about the remaining columns (I’d already removed the 13 lookup columns from ##Results):
SELECT
[var]
,HasNULL = SIGN(SUM(IIF([value] IS NULL, 1, 0)))
,NumCats = COUNT(1)
,NumNumeric = SUM(ISNUMERIC([value]))
,MinVal = MIN([value])
,MaxVal = MAX([value])
,MinLen = MIN(LEN([value]))
,MaxLen = MAX(LEN([value]))
,NumWithDP = SUM(CASE WHEN CHARINDEX('.',[value]) > 0 THEN 1 ELSE 0 END)
,NumWithSN = SUM(CASE WHEN PATINDEX('%[0-9]e[+-][0-9]%',[value]) > 0 THEN 1 ELSE 0 END)
,NumWithNeg = SUM(CASE WHEN LEFT([value],1) = '-' THEN 1 ELSE 0 END)
FROM ##Results
GROUP BY [var]
The code is fairly self-explanatory: var is the column of interest, and we’re counting the number of distinct instances of values where the value is numeric, or contains a period (decimal point), or scientific notation (‘Xe-Y’), or a minus sign at the start. We also want to know the min/max alphabetic values (for identifying 0/1 or N/Y), and the min/max length of the values (for deciding between FLOAT and DECIMAL).
Using this result set, we can say:
- If there are only 2 categories (or 3 including NULL), and the min/max values are 0/1 or N/Y, then we’ll treat this column as a BIT
- If there are no non-numeric values, and any string contains scientific notation, or contains a decimal point and is longer than 18 characters, we’ll treat this as a FLOAT
- If there are no non-numeric values, and no decimal points, then we’ve either got a BIGINT, INT, SMALLINT or TINYINT (not forgetting that TINYINTs can’t be negative, so we check that the first character isn’t a minus sign
This takes care of over half the columns.
Numeric types
We’ve already determined some of the numeric types, but we need to investigate further. Mainly, we’re concerned with identifying the correct precision/scale parameters for DECIMAL types. Note that the first CTE only considers numeric columns we haven’t identified the correct types for yet.
;WITH cte_UnknownOnly AS ( SELECT r.[var] ,floatval = CAST(r.[value] AS FLOAT) ,lp = LEFT(r.[value], CHARINDEX('.', r.[value])-1) ,rp = SUBSTRING(r.[value], 1+CHARINDEX('.', r.[value]), 255) FROM ##Results r WHERE r.var IN(... {unknown numeric columns only}... )) SELECT r.[var] ,MinAsFLOAT = MIN(r.floatval) ,MaxAsFLOAT = MAX(r.floatval) ,MinLenLP = MIN(LEN(r.lp)) ,MaxLenLP = MAX(LEN(r.lp)) ,MinLenRP = MIN(LEN(r.rp)) ,MaxLenRP = MAX(LEN(r.rp)) ,NumDistRP = COUNT(DISTINCT r.rp) ,MinINTLP = MIN(CAST(r.lp AS INT)) ,MaxINTLP = MAX(CAST(r.lp AS INT)) ,MinINTRP = MIN(CAST(r.rp AS INT)) ,MaxINTRP = MAX(CAST(r.rp AS INT)) FROM cte_UnknownOnly r GROUP BY r.[var]
where LP refers to the piece on the left of the decimal point (the integer part), and RP is the piece on the right (the fractional part).
From this result set, it’s easy to work out the correct parameters for DECIMALs using MaxLenLP and MaxLenRP. NumDistRP is useful for deciding whether to simplify some types, e.g. salaries are usually given as whole numbers, but a few may contain fractional parts due to calculations, and you may wish to round the figures for simplicity.
This step took care of the rest of the columns — we now know the correct datatypes for the whole dataset.
Wrap-up
I hear you say: “This looks like a lot of work, I can eyeball the column types faster and just use the wizard.” Good luck to you, I say — I’ve spent far too many hours of my life looking at unhelpful error messages from the Import wizard. And what if you’ve got multiple CSVs with over a thousand columns in each? It’d take days to get all the types correct. This code gives me all the control over the datatypes I could want. (Consider also that I generate the INSERT/SELECT statements from the same config table; I’ve omitted the details here to save space.)
Could I ‘product-ise’ this to make it a single piece of code for anyone to run? Sort of, but not really. There are so many edge cases and ‘quirks’ to cater for. As an example here, the columns prefixed with ‘AMT_REQ_CREDIT_BUREAU’ are presented in the data as having one decimal place, but in reality, they’re all integers (as they’re counts of enquiries).
Note that if the CSV file is too big, you could restrict the categorisation to the first 1000 rows (say). This would probably be ok for well-behaved datasets… but when was the last time you got a well-behaved dataset to work on?
Finally, an anecdote: I once was involved in a project to continuously transfer data from one internal system (Microsoft Dynamics) to another (our SQL Server instance) — the ‘official’ Microsoft connector was unreliable, and flaked out several times a week. The company chose a third-party provider that had a product they claimed could transfer data between hundreds of different systems, and did exactly what we needed — or so we thought. Turns out, after we built our import layer, the product only transferred the data stripped of all formatting, i.e. we received only strings into the target system, whether the original data had been numbers, dates or text. Much swearing ensued! We couldn’t believe this was correct, and the provider was surprised that we were annoyed (“that’s how everyone does it” — is that true? Let me know if you think so…), and we then had to write a ton more code to convert the strings back to the datatypes we needed [which was where I first realised you could use SQL to work out the types]. The lesson I take away is: always check even your most utterly basic assumptions!
Converting R code to Python: A Test
Background
I’ve been using R as my statistics programming environment for decades. In fact, I started out using its predecessor, an earlier (non-open source) program called S. In the last 10 or so years, the role of data scientist has appeared, and in the main, data scientists use the Python programming language, which comes with its own many statistical libraries. In terms of statistics, there’s a huge overlap in the capabilities of R and Python — pretty much anything you can do in R, you can do in Python, and vice-versa. Of course, Python is also used everywhere these days in places you wouldn’t consider using R, e.g. building apps or websites.
In 2020, I completed a few Python modules at DataCamp, but haven’t needed to use it much since. However, Python is pretty much the #1 requirement when it comes to applying for data science positions, so I need to get comfortable with it.
Where I have my own (fairly extensive) library of R functions for various modelling, credit risk and maths purposes, it’d be nice to port all that code to Python — and even nicer if it could be done with as little effort as possible on my part! 😀 So let’s see how we get on with a small-ish function.
The function in R
In the 90s, my MSc dissertation was concerned with exact tests in contingency tables: see the wiki entry Fisher’s exact test for more details. In the PhD thesis of Dr Danius Michaelides, Exact Tests via Complete Enumeration: A Distributed Computing Approach, he describes an algorithm that enumerates integer partitions, subject to constraints (see Section 2.3.2 and Figure 2.2). This algorithm is used in the enumeration of contingency tables with fixed margins.
I’ve recreated this algorithm from his description. The function partitions_with_constraints takes two parameters: v, an array of maximum values, and N, the integer to be partitioned; and returns a matrix of all the possible partitions.
partitions_with_constraints <- function(v, N)
{
vl = length(v);
stopifnot( vl >= 2 );
stopifnot( all(v > 0) );
stopifnot( N <= sum(v) );
cells = rep(NA,vl);
res = c();
i = 1;
while (i > 0)
{
allocated = if(i==1) 0 else sum(cells[1:(i-1)]);
remaining = N - allocated;
if (i == vl) {
# We're at the last cell,
# which can only be the amount remaining.
# Add the cells array to our results.
cells[i] = remaining;
res = rbind(res, cells);
i = i - 1
} else {
if (is.na(cells[i])) {
# Set the cell to the minimum possible
cells[i] = max(0, remaining - sum(v[(i+1):vl]));
} else {
# Otherwise, increment
cells[i] = cells[i] + 1
}
cell.max = min(remaining, v[i]);
if (cells[i] > cell.max) {
# We've hit the maximum; blank the cell, and move back one
cells[i] = NA;
i = i - 1;
} else {
i = i + 1;
}
}
}
# Restore the indices on the rows:
res = matrix(res, nrow=dim(res)[1], byrow=F);
return(res);
}
If we run it using the example from the thesis, we get:
partitions_with_constraints(c(3,1,3),4);[,1] [,2] [,3] [1,] 0 1 3 [2,] 1 0 3 [3,] 1 1 2 [4,] 2 0 2 [5,] 2 1 1 [6,] 3 0 1 [7,] 3 1 0
To explain the output in words: there are 7 ways in which we can partition the number 4 into sums of three numbers, where the first number is between 0 and 3, the second number is between 0 and 1, and the third number is between 0 and 3.
Converting the code with Copilot
For the conversion, I used Microsoft Copilot. (There is a ‘pro’ version, but I’m using the free website version.) If you google Copilot, it seems to be referred to mainly as a ‘chatbot’, but that term feels rather inadequate — so I asked Copilot how to describe itself! It said “Microsoft Copilot is an AI companion designed to assist users by providing information, answering questions, and engaging in conversation.” An ‘AI companion’ is a better description, I think.
Into the ‘Ask me anything’ box, I wrote “Please convert this R function into Python:” and pasted in the code from above. Within a few seconds, it returned the Python code you see below.
The function in Python
Here’s the code that Copilot returned:
import numpy as np
def partitions_with_constraints(v, N):
vl = len(v)
assert vl >= 2
assert all(i > 0 for i in v)
assert N <= sum(v)
cells = [None]*vl
res = []
i = 1
while i > 0:
allocated = 0 if i == 1 else sum(cells[0:i-1])
remaining = N - allocated
if i == vl:
cells[i-1] = remaining
res.append(cells[:])
i -= 1
else:
if cells[i-1] is None:
cells[i-1] = max(0, remaining - sum(v[i:vl]))
else:
cells[i-1] += 1
cell_max = min(remaining, v[i-1])
if cells[i-1] > cell_max:
cells[i-1] = None
i -= 1
else:
i += 1
return np.array(res)
It also output some additional text, describing how the primitive function calls are translated: This Python function should behave similarly to your R function. Please note that Python uses 0-based indexing, unlike R which uses 1-based indexing. This means that some adjustments were needed in the translation. Also, Python does not have a direct equivalent to R’s NA, so None is used instead. The rbind function in R is replaced with list append and conversion to a numpy array in Python. The stopifnot function in R is replaced with assert in Python. The all and sum functions in Python behave similarly to their counterparts in R. The length function in R is replaced with len in Python. The rep function in R is replaced with list multiplication in Python. The max and min functions in Python behave similarly to their counterparts in R.
For me, the most impressive thing is the conversion of arrays from 1-based (i.e. arrays are indexed starting from 1 in R) to 0-based (as in Python, like e.g. C/C++); that wasn’t specified anywhere in the instructions, it just ‘knew’ to do it.
I often use one of the following online sites to run Python (if the code isn’t too big):
I used the first one, pasting the code in, plus the call to the function with the same parameters as in the R version:
print(partitions_with_constraints([3,1,3],4))
[[0 1 3]
[1 0 3]
[1 1 2]
[2 0 2]
[2 1 1]
[3 0 1]
[3 1 0]]
which you can check is the same data as the R version, only the output formatting is different.
Full disclosure: the code didn’t run first time — I’d made a tiny mistake in one of my assertions, that Copilot just translated without picking up on it. And when it did run, there was no output, because I’d forgotten the print(…) around the function call. But these were very minor issues, fixed in seconds.
Copilot generating Python from a description
I want to present another instance of Copilot helping with coding; in this case, not a conversion, but coding an algorithm from a description of what the algorithm should do.
As I’ve mentioned before (in the post Practical queries using binary operations), I occasionally toy around with a Sudoku solver I’ve written in SQL. There’s one piece of cell-checking code I haven’t written yet, so could Copilot write it for me?
My prompt:“I am writing a Sudoku solver. For each remaining cell, I have a list of possible values for that cell. For example, I have a row where four cells have been filled in: 1,4,6 and 8. The remaining possible cell values are (3,7),(2,3,5),(2,3,9),(5,9),(5,7,9) , where parentheses delimit cells. What algorithm can I use to find all possible combinations of cell values? E.g. for my example here, 3,2,9,5,7 is a possibility.”
Copilot wrote: You can use a recursive backtracking algorithm to find all possible combinations of cell values. Here’s a Python function that does this:
def solve_sudoku(possible_values, index=0, solution=[]):
if index == len(possible_values):
print(solution)
return
for value in possible_values[index]:
if value not in solution:
solve_sudoku(possible_values, index + 1, solution + [value])
possible_values = [(3,7),(2,3,5),(2,3,9),(5,9),(5,7,9)]
solve_sudoku(possible_values)
Looks promising… here’s the output when I run the code at Online Python:
[3, 2, 9, 5, 7]
[3, 5, 2, 9, 7]
[7, 2, 3, 5, 9]
[7, 2, 3, 9, 5]
[7, 3, 2, 5, 9]
[7, 3, 2, 9, 5]
It worked, first time.
Then, I asked if it could convert the code to SQL:
SQL is not designed for this type of recursive computation... That being said, you can use recursive Common Table Expressions (CTEs) in SQL for some types of recursive problems. However, the problem you’re trying to solve involves backtracking, which is not straightforward to implement in SQL.
Oh well, you can’t win them all! [I’m not entirely sure how I’m going to convert it to SQL, but the Python code has given me some ideas, so that’s better than nothing.]
Final thoughts
This all worked much better than I thought it would, and the odds are very good that I can convert all my R code to Python without too much work. Sure, the algorithms above aren’t that complicated, but none of my R code is that complicated; most of the functions are wrappers around calls to R libraries. If direct conversion doesn’t work, I can try asking Copilot to recreate the code from a text description of the input/output.
Applying an XSLT to XML in SQL Server
Posted by sqlpete in coding, systems, process, architecture, scorecards on March 5, 2024
XML, XSD and XSLT
I’ve mentioned a few times how much I like working with XML inside SQL Server. Using XML, you can store complicated formats that would be a real pain to replicate as standard normalised tables. However, there are a couple of limitations:
- You can’t validate XML ‘on the fly’ using XSDs; an XSD is an XML Schema Definition (XSD), a way to “describe and validate the structure and content of an XML document”. You can create XML schema collections in SQL Server, but they’re created and modified like other static objects (e.g. tables, functions, sprocs); it’d be nice to have something more dynamic. I’ve covered XSDs before: XSDs FTW.
- You can’t apply XSLTs (eXtensible Stylesheet Language Transformations) which would allow you to transform XML from one structure to another. You can achieve some limited transformation by manipulating individual XML nodes, but it’s messy and long-winded. XSLTs are nicer and built for the job.
Both XSDs and XSLTs are very standard tech, nearly 30 years old, and supported nearly everywhere. (Well, not natively in SQL Server!)
So why do I want to be able to use XSLTs and XSDs?
Background
In the dim and distant past, I was one of a small team of data scientists for a finance company that owned and managed several lenders. We had to deal with the output of several existing scorecards and rulesets (as well as building new and better ones), and, frankly, our databases got messy very quickly, and started to be a barrier to getting things done.
I had an idea: to consolidate all the scorecards (and input/output), using an XML framework within our SQL Server instance. XML manipulation would be needed, for which we could elegantly use XSLTs. I presented a working model of this idea to the CTO… and he didn’t like it. 😦
Luckily, I’d been contacted by the CTO of another lending company who wanted me to go and work for them; they had been assessing potential customers solely via rulesets (very common for start-up lenders at the time), and they needed ‘proper’ credit risk scorecards, which I’ve been building for years. But, crucially, they also needed a mechanism to process the application data through the scorecards — and I knew I could use my XML/XSLTs set-up for this.
The Scorecard Engine
My scorecard sub-system, powered entirely by SQL Server, I referred to as ‘The Scorecard Engine’ (so original 🙄), but it could process anything that could be coded around XML and XSLTs. There were several transform/validation steps from data input (credit files + customer-supplied data + what we knew about the customer already) to returning a final ‘yes/no’ approval; I kept track of all the inputs, intermediate data, and outputs (using the Request / Response pattern), hence debugging at any stage was simple (and I created a suite of scripts purely for that purpose).
The XSLT function
I’m just going to focus on the XSLT functionality here; the original assembly also had other functions to validate XSDs (i.e. was it a valid Schema Definition format?), and to validate XML against XSDs.
As you’ve probably guessed, the functions were built using a SQLCLR assembly; see my recent post, Inverting a matrix in SQL Server for the fun I had creating the assembly in Visual Studio — all those comments apply here(!)
Here’s the code for ApplyXSLT, which takes two XML datatypes (the source XML, and the XSLT), and returns transformed XML.
using System;
using System.Data.SqlTypes;
using System.Xml;
using System.Xml.Schema;
using System.Xml.Xsl;
using System.IO;
using System.Text;
public partial class UserDefinedFunctions
{
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlString ApplyXSLT(SqlXml inputXML, SqlXml inputXSLT)
{
XslCompiledTransform proc = new XslCompiledTransform();
using (var txr = inputXSLT.CreateReader())
{
proc.Load(txr);
}
StringWriter stringWriter = new StringWriter();
XmlTextWriter xmlWriter = new XmlTextWriter(stringWriter);
using (var ixr = inputXML.CreateReader())
{
proc.Transform(ixr, xmlWriter);
}
return new System.Data.SqlTypes.SqlString(stringWriter.ToString());
}
}
Full disclosure:
- Like all good developers, I am liberally ‘inspired’ by stackoverflow and similar places, I might have borrowed some lines from e.g. this stackoverflow post.
- This isn’t the ‘production’ version of the function. The final version that was published to SQL Server had a thorough vetting by experienced C# devs who know far more about these things than I do. The code above works perfectly on my local PC, though.
Using the function in SQL Server
So how do we use the CLR function in SQL Server? Below is a toy example that takes a very simple piece of XML, and transforms it using an XSLT:
DECLARE @inputXML XML DECLARE @inputXSLT XML SET @inputXML =' <application> <person> <firstName>Pete</firstName> <lastName>Tonkin</lastName> </person> </application>'SET @inputXSLT ='<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <Customer> <FullName><xsl:value-of select="concat(//person/firstName,'' '',//person/lastName)"/></FullName> </Customer> </xsl:template> </xsl:stylesheet>'DECLARE @resultXML XML SET @resultXML = dbo.ApplyXSLT(@inputXML, @inputXSLT) SELECT @resultXML AS resultXML GO
which returns:
<Customer>
<FullName>Pete Tonkin</FullName>
</Customer>
The production XML files were up to several MB in size, and the scorecard XSLTs were several hundreds of lines long; but end-to-end, the whole process only took 150-200 milliseconds per application (which involved several rounds of applying XSLTs to XML). Not lightning fast, but perfectly adequate.
And they all lived happily ever after
I rarely blow my own trumpet, but within six weeks of me joining the new company, they had two new fully-tested scorecards (one for each loan product), along with the Scorecard Engine deployed into the main application pipeline. It worked, flawlessly — not a single bug or unexpected result in all the years it was in operation. As usual, this was down to extensive pre-release testing: I literally spent 2-3 weeks running old data through it before it was put live, looking for errors and surprises in the data.
As I recall, the only problem we ever had was when the credit bureau we used (one of the top 3) updated the layout of the credit files they sent us, and miscommunicated the change, which meant an outage for an hour or two while we hurriedly patched our configuration files. (I won’t be caught out like that again!)
At one point, I had plans to turn the Scorecard Engine into more of a self-contained product (rather than just something that lived inside SQL Server), but it never transpired. There’s a massive amount of work that has to be done to turn a few thousand lines of GUI-less code, into a shiny standalone application.
Notes about using RESTORE VERIFYONLY
Recently, I decommissioned the entire data estate for a business*, the end result being a disk-full of database .BAK files that needed restoring elsewhere. Prior to restoration, I wanted to test the files, and check that the files we’d been sent were correct.
* One of the most painfully protracted projects I’ve ever been involved in, but that’s for another day…
Now, as I’ve mentioned many times before, I am not a DBA — but like most devs, I have to dip my toe in the water every once in a while, so it fell to me to verify the dozens of .BAK files. I’m not going to reproduce all my code here, but I’ll go over the main points.
RESTORE VERIFYONLY
SQL Server has the command RESTORE VERIFYONLY which “verifies the backup but does not restore it, and checks to see that the backup set is complete and the entire backup is readable”. The (very simple) syntax is:
RESTORE VERIFYONLY FROM DISK = 'C:\folder\backupfile.bak'
There’s some more detail here at the SQL Server Backup Academy site; also check out SQL interview questions on database backups, restores and recovery – Part III from SQLShack.
My first problem: each database backup had two .BAK files associated with it. According to the company that generated the backups, this was due to them using ‘streams’, and splitting the backup into two files “reduces the time it takes to generate the backup”, they said. (I know the backups contain the data file (MDF) and the log file (LDF), but this isn’t the reason for having two files.) Luckily, having multiple .BAK files isn’t an issue, we can just add extra DISK parameters:
RESTORE VERIFYONLY FROM DISK = 'C:\folder\backupfile1.bak'
, DISK = 'C:\folder\backupfile2.bak'
I run this and get:
Attempting to restore this backup may encounter storage space problems.
Subsequent messages will provide details.
The path specified by "H:\DATA\myDatabase.mdf" is not in a valid directory.
Directory lookup for the file "I:\LOGS\myDatabase_log.ldf" failed with the
operating system error 2(The system cannot find the file specified.).
The backup set on file 1 is valid.
So it looks like, even though we’re not actually restoring the database, it doesn’t like that the original database paths don’t exist. To get round this, we need to know the logical names of the files within the backup, and we can then add MOVE parameters to RESTORE VERIFYONLY. To see the logical names, we use a different command, RESTORE FILELISTONLY:
RESTORE FILELISTONLY FROM DISK = 'C:\folder\backupfile1.bak'
, DISK = 'C:\folder\backupfile2.bak'
which returns a recordset with 2 rows and 22 columns; the first column is LogicalName, which is what we need; let’s say the logical names are MyDatabase and MyDatabase_log. Our VERIFYONLY command becomes:
RESTORE VERIFYONLY FROM DISK = 'C:\folder\backupfile1.bak'
, DISK = 'C:\folder\backupfile2.bak'
WITH FILE = 1,
MOVE N'MyDatabase' TO N'C:\tmp\myDatabase.mdf',
MOVE N'MyDatabase_log' TO N'C:\tmp\myDatabase_log.ldf'
where we’ve specified we’re MOVE-ing our files to some dummy files in our temp directory, C:\tmp\. (During all the testing, I didn’t see any files appear in this temp directory, not even briefly, so I don’t know why this step is necessary really.) Running the above, we get:
The backup set on file 1 is valid.
Unsurprisingly, the time it takes to verify a backup is proportional to its size; for a database with two 30 GB .BAK files, it took 11 minutes on my very old PC.
NB: FILE refers to the ‘backup set file number’, which for all our .BAK files, was 1 — if I changed it to 2, I got the error message “Cannot find file ID 2 on device”.
Looping over all databases
Of course, rather than run these commands dozens of times, I’d like to automate as much as I can — so I wrote code that did the following:
- Got the full list of .BAK files using xp_dirtree
- Turned the list of files into a ‘nice’ temp table that I could loop over, one row per database.
- For each row in the temp table (i.e. database):
- Call RESTORE FILELISTONLY to get the logical names
- Using these, call RESTORE VERIFYONLY
Calling the RESTORE commands
I built my RESTORE FILELISTONLY code as a SQL string, EXEC-ed that, and stored the returned recordset in a table variable. See this very useful comment on stackoverflow for the table definition I used.
However, you can’t do exactly the same with RESTORE VERIFYONLY. You can EXEC the SQL string, as above, but if you try and store the results of the EXEC, you get:
Msg 3021, Level 16, State 0, Line 203
Cannot perform a backup or restore operation within a transaction.
Msg 3013, Level 16, State 1, Line 203
VERIFY DATABASE is terminating abnormally.
It looks like most people recommend putting the command in a TRY/CATCH block, something like the following:
BEGIN TRY RESTORE VERIFYONLY FROM DISK = @file1, DISK = @file2 WITH FILE = 1 , MOVE @Logical1 TO @tmp1 , MOVE @Logical2 TO @tmp2 END TRY BEGIN CATCH... error handling here...END CATCH
As you can see above, you can call RESTORE with @ variables, you don’t have to build a string and EXEC it — I just like to do that wherever possible, so I can PRINT the strings initially, therefore I know exactly what commands I’m going to be running.
SQL Server Full-Text Search
Posted by sqlpete in architecture, coding, systems on February 22, 2024
If you’re searching within text (string) data in SQL Server, the easiest method is to use the LIKE operator with the wildcard ‘%’ character, e.g.:
SELECT * FROM Customers WHERE FirstName LIKE 'Pete%'
will return every customer with the first name Pete or Peter, plus less common forenames like Peterjohn and Peterson. The search string (‘Pete%’) can contain multiple wildcards, and can be used to look for ranges or sets of characters. LIKE is quite powerful, although sadly not as powerful as a full-featured regular expression parser (something that Unix/Linux scripters will be very familiar with). More importantly, LIKE can’t always use column indexes that you think might be appropriate. In the above query, if FirstName was indexed, then that index would be used, but if the search string was e.g. ‘%illy’ (looking for ‘Milly’, ‘Gilly’, ‘Tilly’ or ‘Billy’), then it wouldn’t.
For a more high-powered approach to searching text within database tables, SQL Server has Full-Text Search. From that link:
Full-text queries perform linguistic searches against text data in full-text indexes by operating on words and phrases based on the rules of a particular language such as English or Japanese. Full-text queries can include simple words and phrases or multiple forms of a word or phrase.
I last used Full-Text Search a very long time ago — maybe in the days of SQL Server 7.0! — so I thought it was time to refresh my knowledge.
The dataset
I needed a reasonably large dataset for testing, so I downloaded the Free Company Data Product,
which is a “data snapshot containing basic company data of live companies on the register” at Companies House — basically, a CSV of every company currently incorporated here in the UK. The dataset I downloaded, dated 2024-02-07, was 452Mb zipped, 2.5Gb unzipped, and contains 5,499,110 rows and 55 columns.
After downloading and unzipping, I imported the CSV into SQL Server, then transferred it to a table with appropriate datatypes, also doing some tidying like removing NULL columns, and normalising out some categories to lookup tables. My main cleaned-up table is called cd.CompanyData (‘cd’ is the schema).
Not that it matters for what I’m doing here, but the data is pretty ropey in places; for example, the ‘previous name’ date fields unexpectedly switch from yyyy-mm-dd to dd/mm/yyyy. There are lots of duff postcodes, countries can have several slightly different names, and the address data is generally fairly low quality. For an important dataset from an official government source, I expected a lot better! If I was going to use this data in a professional setting, it’d take me a couple of days and a high-quality address cleaner to make it acceptable.
Creating the full-text index
I’m going to assume that you have the Full-Text Search component installed; it was literally a matter of ticking a checkbox on installation of SQL Server 2022 Developer edition. To check if it’s installed on your SQL Server instance, run:
SELECT FULLTEXTSERVICEPROPERTY('IsFullTextInstalled')
‘1’ means yes, ‘0’ means no.
Firstly, we have to create a Full-Text Catalog. Quote: “You have to create a full-text catalog before you can create a full-text index” — it’s merely a logical container for the full-text indexes we’ll create. In practice, it’s one line of SQL:
CREATE FULLTEXT CATALOG myFirstFullTextCatalog AS DEFAULT
Now we can create our first full-text index; we need three things: the table name (cd.CompanyData), the column we want to index (CompanyName) and the name of a unique key on that table (we can use our primary key, PK_cd_CompanyData):
CREATE FULLTEXT INDEX ON cd.CompanyData(CompanyName)
KEY INDEX PK_cd_CompanyData
WITH STOPLIST = SYSTEM
See CREATE FULLTEXT INDEX for more details. Note that we didn’t have to specify the catalog, as we’ve already declared a default. (Also, it doesn’t have to be a table we’re indexing, we can also add full-text indexes to indexed views.)
What does ‘STOPLIST = SYSTEM’ mean? The STOPLIST is a list of words that aren’t indexed, words like ‘and’, ‘but’, ‘in’, ‘is’. To see the SYSTEM list we’ve used here:
SELECT * FROM sys.fulltext_system_stopwords WHERE language_id = 1033
For me, it returns 154 rows, a list of words and some single characters. (NB: 1033 refers to English) You can curate your own STOPLISTs: Configure and Manage Stopwords and Stoplists for Full-Text Search
IMPORTANT: You can only add one full-text index to a table (or indexed view), but you can have multiple columns per index.
Using the index
You’ll notice that the CREATE FULLTEXT INDEX statement returns immediately; that doesn’t mean the index has been created that quickly, just that the indexing process has started. To keep an eye on the progress, I use the code from this stackoverflow answer. (For the index above, it took a couple of minutes on my old and severely under-powered Windows 10 PC; for multiple columns, it a took a bit longer.)
There are a number of ways to query the index: see Query with Full-Text Search, and Full-Text Search and Semantic Search Functions. Here, we’ll use the table function FREETEXTTABLE.
Let’s query the data, and look for all companies with the word ‘Tonkin’ in, order them by newest incorporated first:
;WITH cte_Search AS
(
SELECT
ft.[KEY]
,ft.[RANK]
FROM FREETEXTTABLE(cd.CompanyData, CompanyName, 'Tonkin') ft
)
SELECT
c.CompanyNumber
,c.CompanyName
,c.IncorporationDate
,ft.[RANK]
FROM cte_Search ft
JOIN cd.CompanyData c
ON c.CompanyNumber = ft.[KEY]
ORDER BY c.IncorporationDate DESC
There are 30 results, first 16 shown here:
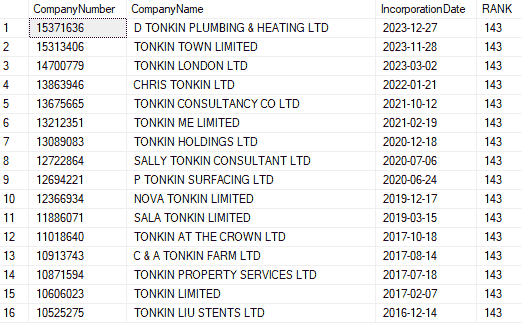
The results are returned within a fraction of a second; the equivalent query using LIKE took nearly 10 seconds.
Aside: Why have I written the query using a CTE, instead of a simple JOIN? When researching this post, I came across this from Brent Ozar: Why Full Text’s CONTAINS Queries Are So Slow
Apart from the increase in speed, the full-text index includes related words, e.g. if I change the query to search for ‘machine’, I get 2153 results where the company names contain ‘MACHINE’, ‘MACHINES’ and ‘MACHINING’. If I search for ‘move’, I get 2497 results where the company names contain ‘MOVE’, ‘MOVING’, ‘MOVED’, ‘MOVES’ and ‘MOVERS’.
But what’s going on with the RANK column? Excellent question, why are they all the same number? It’s to do with the query string we’re passing to FREETEXTTABLE; if it was more complicated, e.g. ‘move OR clean’, then I get eight different values for RANK: 9,13,17,24,30,40,41,43. This page, Limit search results with RANK, has some interesting tidbits.
Loads more to do…
I’ve only lightly scratched the surface here; I know from experience that Full-Text Search is something to seriously consider for a production system, but I’d like a few days of playing around with real data, and real use-cases, before committing. If you’ve an on-going need to locate pieces of text in a large table (e.g. customer search functionality), there are a few things that can be done without installing Full-Text Search:
- Ensuring current indexes are adequate, and actively being used by the SQL engine
- Indexing the first few characters of a string
- Splitting out words or other parts of strings into a separate table and indexing that
- Caching the most popular searches
- Storing or replicating the data to a Memory-Optimized Table
- Hashing words, pairs/triples of words, or full phrases, and indexing the hashes
- Enforcing other criteria to cut-down the search space, e.g. live customer? Applied this year?
and I’m sure I can come up with a few more, given time!
Inverting a matrix in SQL
As long ago as yesterday, I wrote:
I expect someone somewhere has converted pre-existing Fortran or C/C++ code into pure T-SQL. (The algorithm is fairly straightforward, so I doubt it’s that hard to do the conversion.)
Since writing those words, my brain has done nothing but nag at me, so guess what I did this morning?
NB: T-SQL is Microsoft’s own version of SQL — they’re close, but not exactly the same thing. I’ve left the title of the post as ‘SQL’ not ‘T-SQL’, because it should be straightforward to convert the guts of the code to generic SQL, if needed.
Picking an algorithm
No need to come up with my own matrix inversion algorithm, there are plenty to choose from; a google search led me to An Efficient and Simple Algorithm for Matrix Inversion by Farooq and Hamid, from 2010. Here’s their algorithm, written in C, from their paper:

It looks beautifully simple, and therefore, should be pretty easy to convert to SQL!
Conversion to SQL
Firstly, it’d be helpful to have a ‘matrix’ SQL type:
CREATE TYPE MatrixType AS TABLE
(
[row] INT NOT NULL
,[col] INT NOT NULL
,[value] FLOAT NOT NULL
,PRIMARY KEY CLUSTERED ([row],[col])
)
Using this type for my input parameter, here’s my conversion of Farooq and Hamid’s code (note that I’m using a function, not a stored procedure):
CREATE FUNCTION dbo.fn_InvertMatrix
(
@matrix MatrixType READONLY
)
RETURNS @result TABLE
(
[row] INT NOT NULL
,[col] INT NOT NULL
,[value] FLOAT NOT NULL
,PRIMARY KEY CLUSTERED ([row],[col])
)
AS
BEGIN
DECLARE @wkgMatrix MatrixType
INSERT @wkgMatrix([row],[col],[value])
SELECT [row],[col], [value]
FROM @matrix
DECLARE @size INT = (SELECT MAX([row]) FROM @wkgMatrix)
DECLARE @det FLOAT, @pivot FLOAT
,@p INT, @i INT, @j INT
,@mat_pj FLOAT, @mat_ip FLOAT
SET @det = 1.0
SET @p = 1
WHILE(@p <= @size)
BEGIN
SELECT @pivot = [value]
FROM @wkgMatrix
WHERE [row] = @p AND [col] = @p
SET @det = @det * @pivot
IF (ABS(@det) < 1e-5)
BEGIN
RETURN
END
UPDATE @wkgMatrix SET [value] = -[value]/@pivot WHERE [col] = @p
SET @i = 1
WHILE (@i <= @size)
BEGIN
IF (@i <> @p)
BEGIN
SELECT @mat_ip = [value] FROM @wkgMatrix WHERE [row] = @i AND [col] = @p
SET @j = 1
WHILE (@j <= @size)
BEGIN
IF (@j <> @p)
BEGIN
SELECT @mat_pj = [value] FROM @wkgMatrix WHERE [row] = @p AND [col] = @j
UPDATE @wkgMatrix SET [value] = [value] + (@mat_pj * @mat_ip)
WHERE [row] = @i AND [col] = @j
END
SET @j = @j + 1
END
END
SET @i = @i + 1
END
UPDATE @wkgMatrix SET [value] = [value] / @pivot WHERE [row] = @p
UPDATE @wkgMatrix SET [value] = 1.0/@pivot WHERE [row] = @p AND [col] = @p
SET @p = @p + 1
END
INSERT @result([row],[col],[value])
SELECT [row],[col], [value]
FROM @wkgMatrix
RETURN
END
Notes about this conversion:
- I’ve written the code as a function, it should be trivial to convert to a sproc if needed.
- I’ve removed a couple of loops from the original version; I think someone with time on their hands could make the code even smaller? Maybe a recursive CTE could work?
- There’s very little error-checking, e.g. I should at least check that the matrix is square. It’s not production-ready code — if it was, there’d be comments and headers.
So, does the code actually work? How can we test it? Let’s generate a random square matrix (from 2×2 up to 9×9), invert it, then check that when multiplied together, we get the identity matrix — then let’s do this thousands of times.
We’ll need a helpful SQL function to multiply two matrices together:
CREATE FUNCTION dbo.fn_MatrixMultiply
(
@m1 MatrixType READONLY
,@m2 MatrixType READONLY
)
RETURNS TABLE
AS
RETURN
(
SELECT
m1.[row]
,m2.[col]
,[value] = SUM(m1.[value] * m2.[value])
FROM @m1 m1
JOIN @m2 m2
ON m2.[row] = m1.[col]
GROUP BY m1.[row], m2.[col]
)
And we’re ready — let’s do a few thousand iterations, here’s my testing code:
DROP TABLE IF EXISTS #results
GO
CREATE TABLE #results
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED
,size INT NOT NULL
,[diag] FLOAT NOT NULL
,[offdiag] FLOAT NOT NULL
)
GO
SET NOCOUNT ON
DECLARE @Z INT = 1
DECLARE @m1 AS MatrixType
DECLARE @m2 AS MatrixType
DECLARE @mr AS MatrixType
DECLARE @size AS INT
WHILE(@Z <= 3000)
BEGIN
SET @size = 2 + ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT)) % 8 -- random from 2 to 9
DELETE FROM @m1
INSERT @m1([row],[col],[value])
SELECT x.r AS [row], y.c AS [col]
,[value] = CAST(CAST(CAST(NEWID() AS VARBINARY) AS INT) AS FLOAT)/1000000000.0
FROM (
VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)
) x(r)
CROSS JOIN (
VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)
) y(c)
WHERE x.r <= @size
AND y.c <= @size
DELETE FROM @m2
INSERT @m2([row],[col],[value])
SELECT [row],[col],[value] FROM dbo.fn_InvertMatrix(@m1)
DELETE FROM @mr
INSERT @mr([row],[col],[value])
SELECT [row],[col],[value] = ROUND([value],7)
FROM dbo.fn_MatrixMultiply(@m1, @m2)
INSERT #results(size,diag,offdiag)
SELECT
size = @size
,diag = (SELECT SUM(CASE WHEN [value] = 1.0 THEN 1 ELSE 0 END)
FROM @mr WHERE [row] = [col])
,offdiag = (SELECT SUM([value]) FROM @mr WHERE [row] <> [col])
SET @Z = @Z + 1
END
GO
If everything has worked as expected, then in every case, the size of the matrix will be the same as the sum of the diagonal elements, and the sum of the off-diagonal elements will be zero:
SELECT
N = COUNT(1)
,diag_ok = SUM(CASE WHEN size = diag THEN 1 ELSE 0 END)
,offdiag_ok = SUM(CASE WHEN offdiag = 0 THEN 1 ELSE 0 END)
FROM #results
GO
N diag_ok offdiag_ok
----------- ----------- -----------
3000 3000 3000
All good, looks like the code has worked perfectly!
Finally
Again, I’ve done nothing clever here, just piggy-backed off someone else’s good work. But now I’ve got my own ‘native’ SQL function to play with, no more messing about with SQLCLRs — quite the relief!
A few final points:
- Although I think the code works fine, I need to extensively compare the results with my SQLCLR function. For instance, my random matrices didn’t have any zeros in, and I restricted the range of the cell values, what happens with large values? Or a mixture of very big and very small values? What about much larger matrices?
- How fast is the code? It doesn’t matter for my use-case, but it might for other people’s. Maybe the SQLCLR function is much faster.
- Not all matrices are invertible, why didn’t I get any errors? This is answered here: Probability question: what are the odds that a random nxn matrix is invertible?
- Often, the determinant of the matrix is useful, I should work out a way to return that.
- Before converting to SQL, I converted the code to R, and now I really want to make an ‘arbitrary precision version of it, using the gmp library…
- It feels like I should start my own library of SQL functions to work with matrices — one day!
Inverting a matrix in SQL Server
Apologies in advance, this post is a little light on certain details. This is because (a) I don’t have time to write a big, exhaustive piece, that could easily be a 30-page document, and (b) the actual creation of the SQLCLR function in Visual Studio was more akin to witchcraft than coding (I’ll attempt to explain later on…) Also, there’s some waffle around credit risk, you can safely ignore it! 😉
My credit risk use-case
In credit risk, we always want to know what’s going to happen to the loans in our loan book. Will they eventually pay us back, or will they default? Clearly, this is very important information, and you can’t run a successful lending business without it.
Markov chains
One of the ways we predict what’s going to happen, is using a Markov Chain model. We generate a transition matrix from our data, and using matrix arithmetic, repeatedly multiply the matrix by itself to calculate what happens in the future. The Markov property is that the future states of a process only depend on the current state, not the past. (This is also referred to as ‘memoryless’.)
Here’s an example transition matrix that shows the statuses of loans last month, compared to this month.

(An old FD used to call this the ‘Was/Is’ matrix)
The numbers 0 to 6 refer to how many payments behind the customer is, D is default, and S is settled. For example, of the loans that were three payments down last month, 35% stayed three payments down; 4% returned to zero (‘up to date’), and 7% settled their account. None of them went straight to default. Note that the percentages add up to 100 row-wise, but not column-wise.
D (default) and S (settled) are called absorbing states — once you enter them, that’s it, you can’t come back. (In real life, this isn’t true, but we can ignore it here.)
Because of these absorbing states, our Markov chain is a special case, an Absorbing Markov Chain. Using the above transition matrix, we can calculate the long-term probabilities of settlement (repayment) or default for all our loans, given their current position.
To get these probabilities, we need to calculate 

E.g. an up-to-date loan currently has a 6% chance of defaulting. A loan that is 6 payments down only has a 25% chance of being repaid.
Inverting a matrix in Excel
Okay, couldn’t we just use Excel to do these calculations? Excel has an inbuilt function MINVERSE, see here for an example.
In the past, I’d done these calculations for a different loan book, using Excel, and the modelling had worked and told us what we needed to know. For the loan book I was working on now, I wanted to automate the calculations, over several different partitions of the data — for instance, if you have multiple products, then typically you’d need to do the calculations per product. Hence, the requirement to do everything within SQL Server.
Inverting a matrix from within SQL Server
I chose the title of this post carefully: we’re inverting a matrix using SQL Server, but the code isn’t written in SQL (T-SQL) itself. I expect someone somewhere has converted pre-existing Fortran or C/C++ code into pure T-SQL. (The algorithm is fairly straightforward, so I doubt it’s that hard to do the conversion.)
The two methods I’m proposing here both involve installing something to SQL Server itself, which admittedly may not be possible for everyone.
- Executing R code from within SQL Server, an example of running R code is given here. There are several libraries and functions dedicated to inverting matrices; solve from the base installation and inv from the matlib package are two of the most popular.
- Creating a SQLCLR function using C#
It’s the second one we’ll look at for the remainder of this post.
Creating an assembly using SQLCLR
Below is the exact (not terribly well-written) C# code that I used to create an assembly in Visual Studio, that I could then publish to my instance of SQL Server, and then use the function MatrixInvert as I would any other SQL function call.
using System; using System.Data; using System.Linq; using System.Data.SqlClient; using System.Data.SqlTypes; using System.IO; using System.Text; public partial class UserDefinedFunctions { [Microsoft.SqlServer.Server.SqlFunction] public static SqlString MatrixInvert(SqlString matrixAsString) { string[][] strMatrix = (matrixAsString.ToString()).Split(';').Select(x => x.Split(',')).ToArray(); int matrixX = strMatrix.Length; for (int i = 0; i < matrixX; i++) { if (strMatrix[i].Length != matrixX) { throw new Exception("Matrix not square NxN"); } } int matrixSize = matrixX; double[][] matrix = new double[matrixSize][]; for (int i = 0; i < matrixSize; i++) { matrix[i] = new double[matrixSize]; } for (int i = 0; i < matrixSize; i++) { for (int j = 0; j < matrixSize; j++) matrix[i][j] = Convert.ToDouble(strMatrix[i][j]); } double[][] inverseMatrix = MatrixInverse(matrix); double[][] identityMatrix = MatrixIdentity(matrixSize); double[][] product = MatrixProduct(matrix, inverseMatrix); String result = null; Boolean matrixAreEqual = MatrixAreEqual(product, identityMatrix, 1.0E-8); if (matrixAreEqual == true) { for (int i = 0; i < matrixSize; i++) { for (int j = 0; j < matrixSize; j++) { result += inverseMatrix[i][j].ToString(); if (j < (matrixSize - 1)) result += ','; } if (i < (matrixSize - 1)) result += ';'; } } else { result = null; } return (result); }// here: add code from https://jamesmccaffrey.wordpress.com/2015/03/06/inverting-a-matrix-using-c/}
As you’ll no doubt spot, the code is incomplete — see the final comment. Because it was convenient, I used the C# code from James D. McCaffrey’s blog post Inverting a Matrix using C#. (I don’t want to reproduce his code here, you’ll have to grab it for yourself – but you literally don’t have to do anything to it, just copy and paste.) If this code hadn’t been available, I was going to adapt the code in my venerable copy of ‘Numerical Recipes in C’ (current website here).
Other points to note:
- My function MatrixInvert calls the functions MatrixInverse, MatrixIdentity, MatrixProduct and MatrixAreEqual from James D. McCaffrey’s code. My function is not much more than a wrapper around the clever stuff.
- The figures are passed to the function as a single delimited string (comma / semi-colon), and returned similarly. There’s undoubtedly a better way of doing this, but it works.
- The code checks that the original matrix multiplied by its inverse equals the identity, to some tolerance level, and returns null if this isn’t the case.
- There could be more error-checking — there could always be more error-checking!
But how did I get this code into SQL Server? So here come the excuses…
The last time I wrote a SQLCLR (maybe 2 years ago?), I downloaded the latest Visual Studio, created a ‘SQL Server Database Project’, wrote my code, hit ‘Publish’, entered the database details, and it sorta just worked. (Least, that’s how I remember it.) While writing this post, I followed the same path… and it took ages, with a ton of googling throughout. Finally, I got it working again, but it wasn’t a pleasant experience. In the end, I had to manually paste in SQL similar to the following:

and set/unset some configuration values:
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'clr strict security', 0;
RECONFIGURE;
EXEC sp_configure 'clr enabled', 1;
RECONFIGURE;
I’m sure it wasn’t this hard last time!
At this point, the SQL function dbo.MatrixInvert is available for me to use. To test it out, let’s take an integer matrix that has an inverse that only contains integers; I got my example from the blog post “Random Integer Matrices With Inverses That Are Also Integer Matrices. The code below builds up our input matrix (as a string), calls the function, then parses the string that’s returned.
DECLARE @myMatrix VARCHAR(MAX)
SET @myMatrix = '9,21,23,8,18,7,12,7;
8,13,15,5,10,5,9,6;
0,13,11,2,13,1,3,0;
13,11,16,13,6,11,13,10;
11,21,23,7,17,7,13,8;
10,8,12,9,4,8,10,8;
11,16,19,7,12,7,12,8;
6,12,14,6,10,5,8,5'
DECLARE @invertedMatrix VARCHAR(MAX)
SELECT @invertedMatrix = dbo.MatrixInvert(@myMatrix)
SELECT
[row]
,[col] = ROW_NUMBER() OVER
(PARTITION BY [row] ORDER BY GETDATE())
,ROUND(CAST(s.[value] AS FLOAT), 2) AS [value]
FROM (
SELECT [row] = ROW_NUMBER() OVER (ORDER BY GETDATE())
,[value] AS rowStr
FROM STRING_SPLIT(@invertedMatrix, ';')
) x
CROSS APPLY STRING_SPLIT(x.rowStr, ',') s
ORDER BY [row],[col]
GO
The result set has 64 rows, and starts like this:

All good, it matches the inverse from the original blog post!
Of course, you can pass floats into the function, I used this integer matrix because it looked ‘clean’.
One thing I can’t let pass without comment: why the heck have I used ORDER BY GETDATE() in my ROW_NUMBER window function? Because, somewhat unbelievably, SQL Server’s STRING_SPLIT function doesn’t return an ordinal associated with the position, so I’m trying to force it to behave repeatably; see Row numbers with nondeterministic order for more information. In a production setting, I’d probably use my own hand-rolled function to split strings.
An admission of failure
Finally, an admission of failure: not the code, that all worked perfectly, I was able to calculate my inverse matrices and ‘final state’ probabilities. Except… the models didn’t work. I’d started off looking at older data, seeing if I could replicate the state of loans a few years down the line, and I couldn’t get it to work. I split the data into products, into cohorts, by customer attributes, started looking at second and higher order Markov chains (where the ‘present’ doesn’t just depend on the immediate past, but two, three, etc. steps ago), and nothing worked. In the end, I had to admit defeat. A few months later, I was talking to a Financial Director about my lack of success on this particular loan book — and he said he wasn’t surprised, that in his experience, this sort of modelling didn’t work on some shorter-term financial products. That made me feel somewhat better, but I still want to know what the ‘correct’ model was!
Postscript: Several years later, I was chatting with an agent who’d worked in the operations department, who told me that there was a manual component to the status changes (the statuses weren’t the traditional ‘0-6 payments down’) that I wasn’t aware of when I did the original modelling. I can’t put all the blame on this, but it did go some way to explaining the lack of consistency I was seeing in the data, and I should’ve pushed harder to understand it at the time.
A quick review of some sketchy SQL
For a brief time, I have access to some database code from a defunct lending company, that I worked for in the past. While rootling through the code for another reason, I came across a small sproc that I thought it might be interesting to take a look at in some detail, to point out issues with the code – some minor, some less so.
Actually, the sproc (which generated data for a report) had some additional parts to it, but those were almost identical with respect to the issues we’re concerned with here, so we’ll just concentrate on this first part.
Firstly, a caveat: the person who wrote the code was not a native SQL coder, they were a C# developer. It’s been common for many years, especially in smaller companies, for devs to be responsible for most, if not all, of the SQL that gets written. I am absolutely not picking on this coder, and there are certainly more egregious examples I could have used, written by more senior folk! I chose this code because it nicely demonstrates one of my least-favourite SQL patterns, which really comes down to ‘trying to do too much at once, at the expense of performance issues and readability’.
The code

The image above shows a truncated view of the code, click on it to see the full width.
For obvious reasons, I’ve removed the header, which contained the sproc name, the coder’s first name and a too-brief description of the code. Ideally, all sprocs should have headers with lots of information in them, including a change-log (if there’s no source control available).
It doesn’t really matter what the tables and columns are, we’re talking more about the ‘shape’ of the code, how the query is constructed.
The issues
It’s not all bad, let’s start off with the good points.
The good points
- The code uses temp tables for the right reasons. They may not have made the most of it (no indexes, see below), but if a query is complicated enough, I will use temp tables extensively. It helps greatly with readability, and almost always, with performance too.
- The tables are aliased. (i.e. BPM, PST, PT, T) Ok, I prefer lower-case aliases, but that’s minor. Better that than nothing; it’s clear here which table contains which column. I’ve seen code where the entire table name is used as the alias, and it was unreadable. (They missed out the alias on the final ‘Order By’, a small mistake.)
Minor issues
- Magic numbers: Values of ProductIDs are given without any explanation/comment; yes, if you know the codebase, this isn’t a problem, but if you’re new, it’d be helpful to spell out what these values mean.
- Temp table has ‘Temp’ in the name, not really necessary(*)
- There’s no DROP TABLE IF EXISTS statement before CREATE TABLE, which would help with debugging — not strictly necessary, just helpful.
(*) I like my temp tables to not have the same name as ‘real’ tables, just in case a DROP TABLE statement goes awry! I guess putting ‘Temp’ in front of the table name makes this a non-issue.
Less major issues
- Formatting in general; it’s inconsistent and hard to read, e.g. the code extends out past column 300 (and even further in the full code)
- Spelling: It’s ‘instalment’ not ‘installment’; spelling is an issue throughout the entire codebase, they were far from the only culprit
- Date range: I much prefer my date ranges to be ‘right-open’, i.e. [CreatedDate] >= @fromDate AND [CreatedDate] < @toDate (not <=), to make things explicit.
- The temp table doesn’t have a primary key or any indexes; this is one of the main reasons for using temp tables in sprocs, to put your own indexes on that will benefit your individual query
- What’s the point of the Order by LoanDuration clause?
- Lack of comments: There are no useful comments anywhere in the sproc!
More major issues
- They didn’t really understand how the ‘CASE’ statement works
- At the bottom of the query, they’re GROUPing by too many things (!a big ‘code smell’!), which is a consequence of doing the COUNT() in the main query — this is not a nicely written query, it can be greatly improved
Doing too much at once
It’s the last of these major issues I want to concentrate on, as it’s something I see constantly: the coder is trying to do too many things at once, which makes the code impenetrable, hard to debug, and greatly increases the likelihood of the results being wrong.
The intention of the coder was that #Temploandetails had one row per loan (each row of BorrowerProductMapping is an instance of an application/loan). Hence, if I was going to re-write the code, I’d put an appropriate primary key on the temp table, and use one of the following patterns:
SELECT <fields>
FROM [dbo].[BorrowerProductMapping] bpm
OUTER APPLY (
SELECT
NumTerms = COUNT(1)
FROM [dbo].[Terms] ti
WHERE ti.CustomerProductID = bpm.CustomerProductID
GROUP BY ti.CustomerProductID
) t
WHERE <conditions>...
or
SELECT <fields>
FROM [dbo].[BorrowerProductMapping] bpm
LEFT JOIN (
SELECT
ti.CustomerProductID
NumTerms = COUNT(1)
FROM [dbo].[Terms] ti
GROUP BY ti.CustomerProductID
) t
ON t.CustomerProductID = bpm.CustomerProductID
WHERE <conditions>...
The intent is much clearer, doesn’t involve aggregation over everything, and therefore doesn’t involve a large unnecessary GROUP BY clause.
OUTER APPLY vs LEFT JOIN
Note that the two constructs above aren’t identical, they’ll perform differently depending on how much data is in the Terms table. The OUTER APPLY version may do a scan per row of the outer table, which in some circumstances could be expensive. There are many forum and blog posts about this, just google ‘OUTER APPLY versus LEFT JOIN’.
Interesting aside: when writing the code above, I idly left off the ‘GROUP BY’ inside the OUTER APPLY; on the face of it, it’s unnecessary, because we’re already restricting to a single CustomerProductID. However, I did some testing on a limited dataset, and including the GROUP BY results in (a) a different query plan; (b) much better performance and faster execution; and (c) different output — NumTerms is NULL for non-matching IDs if we use GROUP BY, but zero if we don’t use it. I think I understand why the difference exists, but I can’t say it enough: test your code!
What would I do?
I’d test three options. The first two as above, and for a third, I’d initially create a ‘Scope’ temp table with the CustomerProductIDs from the required date range, and use the Scope table to join to the Terms; I can see that the CreatedDate was nicely indexed on BorrowerProductMapping, so the data for the Scope table would come straight from the index, no need to touch the main table at all! Also, for this particular sproc, I could then re-use the Scope table in the other very similar queries (not shown here). I did some testing on small date ranges, and this third option marginally improved performance. But I would not assume that the performance would be automatically improved for large date ranges too — plus there’s also the consideration of the balance to be had between having more code, and marginal performance gains.
The Big Question
Okay, so the code could be improved, does that matter? If it works, it’s not something that need concern us too much, right?
Well, actually, the code is wrong. Not massively, but the complete sproc returns a data set with duplicate rows; maybe these were filtered out by the report, I don’t know.
The cause of the dupes is almost certainly down to writing queries with multiple joins, left joins and aggregations all mixed together in one big query. With a bit more thought and care, it wouldn’t have happened. Even worse is that they clearly didn’t run enough (any?) tests on the output! When writing sprocs like this, you should always pipe the output into a temp table, and check that the data is exactly what you’re expecting (in this case, one row per loan). Ultimately, that’s the worst offense here — you should always test your code!
Fun converting to integers in R
If you work on the programming side of finance, then I expect that you share my sentiment that rounding errors are the bane of our lives. I was writing a function in R to process the calculations in a loan schedule (more on that soon, watch this space), and was rather quickly overwhelmed with figures not adding up. So, I thought it would be a good idea to do as many of the calculations in pence (rather than pounds) as possible; then that way I was only dealing with integers, not floating point numbers.
Why didn’t I use a decimal datatype? Because there isn’t one in R! (See the end of this post.)
Converting to integer values for pence should have solved all the problems, but I was still getting calculation errors. What was going wrong?
Here’s a value which is the un-rounded total interest amount due on a loan:
interest = 621.5518100862391293;
This amount is in pounds — the way that interest (and/or payments) are usually calculated, it’s inevitable that the amount won’t be a whole number of pence. Clearly, we can’t charge 0.181 etc. of a penny, so we round it down. (Good practice says you should always round interest values in the customer’s favour.)
I want to turn that figure from pounds into pence; here I’m after a value of 62155 pence.
I can use the floor function to remove the fractional part of the pence (everything less than 1p):
interest_2dp = floor(interest * 100) / 100; interest_2dp[1] 621.55
Convert it to pence:
interest_pence = 100 * interest_2dp; interest_pence[1] 62155
All good so far.
Now, the datatype of the variable interest_pence is:
class(interest_pence)[1] "numeric"
but my code is expecting an integer. There’s a function, as.integer, in R to do the conversion (that discards anything after the decimal point):
interest_pence_int = as.integer(interest_pence);
which has the value:
interest_pence_int[1] 62154
Wait, what? 62154 not 62155? Where’s the penny gone?
Well, it’s because our previous values haven’t been displayed to full accuracy. We can easily show this:
interest_pence - 62155[1] -7.275958e-12
Therefore interest_pence is slightly less than 62155 — in other words 62154 plus some number that’s nearly-but-not-quite one. Hence when we convert to integer, it discards the fractional part, and we get 62154.
The fix
Basically, it seems this is caused by the division by 100, then the multiplication by 100. If we remove this redundancy, then we get:
floor(interest*100)[1] 62155as.integer(floor(interest*100))[1] 62155
I’m not claiming that all the rounding errors in my code are fixed forever by doing this, I know better than that! However, things are looking much better.
Some notes:
- This all looks a bit trivial, why didn’t I spot it straight away? Simply because in my code, other things were happening between the declarations of interest_pence and interest_pence_int, they were several lines apart.
- This is all very similar to a previous post, where essentially the same thing was happening in SQL: Floats may not look distinct
- I did spend a long time messing with converting the numbers to strings (via sprintf) then truncating them, to see if I could get round the problem that way; but it just made things worse, because sprintf does rounding of its own.
Decimals in R
Sounds unlikely, but it’s true: R doesn’t have a native decimal datatype.
I found this answer to the stackoverflow post “Is there a datatype “Decimal” in R?”, which has some code to create a decimal structure (using an underlying integer64 type), but it didn’t work for me: the line d + as.decimal(0.9) returned an integer64 type, rather than the expected decimal.
There’s also this repo on GitHub, but I didn’t try it out – I didn’t want to introduce more libraries if I could help it.
Another avenue I could’ve tried is using the GNU Multiple Precision Arithmetic package, but again, probably overkill for something that should be so simple!
Using SQL to read an Excel file into SQL Server
There are two obvious ways to get data from Excel into SQL Server:
- Use the Import/Export Wizard in SQL Server Management Studio (SSMS)
- Build up the individual VALUE strings in Excel (the TEXTJOIN function in Excel is very handy for this), and then copy/paste into SSMS (you have to write the INSERT part of the statement yourself)
I use both methods all the time; the second is quicker, but only works for up to a few thousand rows. Currently, I’m working on a spreadsheet that I’m updating frequently, and I want to be able hit ‘execute’ (‘go’) on some SQL code that will do the import, followed by some fairly involved post-processing — all with minimal intervention on my part.
My use case
As I mentioned in my previous post, I’m learning Welsh. So, in an effort to combine two of my interests, in my spare time I’m (very slowly) building a Windows app to help with my learning. It is, of course, powered by a SQL Server back end. Hence I’ve created a bunch of Excel spreadsheets with lists of nouns, verbs, etc., and I want to import them into my SQL Server database, as painlessly as possible. I prefer to develop my databases by dropping absolutely everything, then re-creating all objects and data from scratch every time I make any sort of significant change. I use SQL scripts to load code in from files, and I can add steps at the end to load data in from spreadsheets.
What follows is how I got the Excel file import working — really, I’m just showing you what error messages I encountered along the way, and how I got past each one, with the help of Google, Stack Overflow, etc.
Important caveat: This is all running on my local computer, so I have full control over security and permissions. I wouldn’t recommend doing any of this on a production server without research and testing!
Getting started
My translation data is in the spreadsheet Welsh words.xlsx, on my I: drive. The first sheet is named ‘nouns’. Here is the SQL statement I want to run:
SELECT *
FROM OPENROWSET
(
'Microsoft.ACE.OLEDB.12.0',
'Excel 12.0; Database=I:\Welsh words.xlsx; HDR=YES; IMEX=1',
'SELECT * FROM [nouns]'
)
GO
OPENROWSET is used “to access remote data from an OLE DB data source”. You can find out more about it here (at microsoft.com).
Microsoft.ACE.OLEDB.12.0 is an ‘OLE DB Provider’ … and honestly, no, I don’t really know what that means, other than it’s some clever code that lets one thing talk to another!
When I execute this code in SQL Server Management Studio (SSMS), I get my first error message:
Msg 15281, Level 16, State 1, Line 1
SQL Server blocked access to STATEMENT 'OpenRowset/OpenDatasource' of component
'Ad Hoc Distributed Queries' because this component is turned off as part of the
security configuration for this server. A system administrator can enable the use
of 'Ad Hoc Distributed Queries' by using sp_configure. For more information about
enabling 'Ad Hoc Distributed Queries', search for 'Ad Hoc Distributed Queries'
in SQL Server Books Online.
The important words are ‘security configuration’ — I’ve come across this before, e.g. when I wanted to use the MSXML2.ServerXMLHTTP component, see the post “‘You Can’t Always Get What You Want’ – old tech to the rescue!”. We need to enable ‘Ad Hoc Distributed Queries’ in the configuration, like this:
EXEC sp_configure 'Ad Hoc Distributed Queries', 1 GO-- Configuration option 'Ad Hoc Distributed Queries' changed from 0 to 1. Run the RECONFIGURE statement to install.RECONFIGURE GO-- Commands completed successfully.
I run my SELECT statement again, and get a different error:
Cannot create an instance of OLE DB provider "Microsoft.ACE.OLEDB.12.0"
for linked server "(null)".According to this article at MSSQLTips, I need to set the following configuration option in SQL Server:
EXEC master.[sys].[sp_MSset_oledb_prop] N'Microsoft.ACE.OLEDB.12.0', N'AllowInProcess', 1 GO-- Commands completed successfully.
I run my SELECT statement again, and get:
The 32-bit OLE DB provider "Microsoft.ACE.OLEDB.12.0" cannot be loaded
in-process on a 64-bit SQL Server.So the provider I’m trying to use to access the Excel file is 32-bit, but I need the 64-bit version.
Getting the right provider
In a reply to this Stack Overflow post, “Microsoft.ACE.OLEDB.12.0” cannot be loaded in-process on a 64-bit SQL Server, there’s a link to Microsoft to download the file I need: Microsoft Access Database Engine 2010 Redistributable.
The file I want is AccessDatabaseEngine_X64.exe, and it’s 27.3 MB in size:
The reply says to install the code in passive mode to “prevent the installation from failing if you already have the 32-bit version installed”. Therefore when it finishes downloading, I open up a Command Prompt as administrator, and run:
"C:\Users\Pete\Downloads\AccessDatabaseEngine_X64.exe" /passive /quiet

(Nothing much happens, the mouse pointer maybe shimmies for a few seconds)
Ok, I’ve got the correct provider installed; my SELECT query should work, right?
Msg 7399, Level 16, State 1, Line 1
The OLE DB provider "Microsoft.ACE.OLEDB.12.0" for linked server "(null)" reported an error.
The provider did not give any information about the error.
Msg 7303, Level 16, State 1, Line 1
Cannot initialize the data source object of OLE DB provider "Microsoft.ACE.OLEDB.12.0"
for linked server "(null)".
The solution to this is in another Stack Overflow post: I need to be running SSMS as administrator, so I shut SSMS down (not the server, just the management studio) and re-start SSMS as administrator.
Nearly there
I run my SELECT statement again…
OLE DB provider "Microsoft.ACE.OLEDB.12.0" for linked server "(null)" returned message
"The Microsoft Access database engine could not find the object 'nouns'. Make sure the object
exists and that you spell its name and the path name correctly. If 'nouns' is not a local
object, check your network connection or contact the server administrator.".
Msg 7350, Level 16, State 2, Line 1
Cannot get the column information from OLE DB provider "Microsoft.ACE.OLEDB.12.0"
for linked server "(null)".
A-ha, we’re getting somewhere! The complaint is that it “could not find the object ‘nouns'”, the implication being that it could find other objects? In fact, it’s my fault: my query is wrong, I need a dollar sign ($) after the sheet name:
SELECT *
FROM OPENROWSET
(
'Microsoft.ACE.OLEDB.12.0',
'Excel 12.0; Database=I:\Welsh words.xlsx; HDR=YES; IMEX=1',
'SELECT * FROM [nouns$]'
)
GO
I run this, et voilà, my data:
(Actually, the above shows the data from the first 12 columns, which you can select by changing [nouns$] to [nouns$A:L].)
And that’s it, I can now finally import data from my Excel spreadsheets, and I can add these imports as a step in my database rebuild code.
Some final notes:
- None of the above works if the Excel file is open; it has to be closed, or you’ll get the error “Cannot initialize the data source object”.
- I thought there was a way of using OPENROWSET to return the list of sheet names, but I can’t find it now. That would be very useful!
- You can also connect Excel to SQL Server using Linked Server functionality, but I’ve not tried it — please do let me know if you have.

Recent Comments