Archive for February, 2024
Notes about using RESTORE VERIFYONLY
Recently, I decommissioned the entire data estate for a business*, the end result being a disk-full of database .BAK files that needed restoring elsewhere. Prior to restoration, I wanted to test the files, and check that the files we’d been sent were correct.
* One of the most painfully protracted projects I’ve ever been involved in, but that’s for another day…
Now, as I’ve mentioned many times before, I am not a DBA — but like most devs, I have to dip my toe in the water every once in a while, so it fell to me to verify the dozens of .BAK files. I’m not going to reproduce all my code here, but I’ll go over the main points.
RESTORE VERIFYONLY
SQL Server has the command RESTORE VERIFYONLY which “verifies the backup but does not restore it, and checks to see that the backup set is complete and the entire backup is readable”. The (very simple) syntax is:
RESTORE VERIFYONLY FROM DISK = 'C:\folder\backupfile.bak'
There’s some more detail here at the SQL Server Backup Academy site; also check out SQL interview questions on database backups, restores and recovery – Part III from SQLShack.
My first problem: each database backup had two .BAK files associated with it. According to the company that generated the backups, this was due to them using ‘streams’, and splitting the backup into two files “reduces the time it takes to generate the backup”, they said. (I know the backups contain the data file (MDF) and the log file (LDF), but this isn’t the reason for having two files.) Luckily, having multiple .BAK files isn’t an issue, we can just add extra DISK parameters:
RESTORE VERIFYONLY FROM DISK = 'C:\folder\backupfile1.bak'
, DISK = 'C:\folder\backupfile2.bak'
I run this and get:
Attempting to restore this backup may encounter storage space problems.
Subsequent messages will provide details.
The path specified by "H:\DATA\myDatabase.mdf" is not in a valid directory.
Directory lookup for the file "I:\LOGS\myDatabase_log.ldf" failed with the
operating system error 2(The system cannot find the file specified.).
The backup set on file 1 is valid.
So it looks like, even though we’re not actually restoring the database, it doesn’t like that the original database paths don’t exist. To get round this, we need to know the logical names of the files within the backup, and we can then add MOVE parameters to RESTORE VERIFYONLY. To see the logical names, we use a different command, RESTORE FILELISTONLY:
RESTORE FILELISTONLY FROM DISK = 'C:\folder\backupfile1.bak'
, DISK = 'C:\folder\backupfile2.bak'
which returns a recordset with 2 rows and 22 columns; the first column is LogicalName, which is what we need; let’s say the logical names are MyDatabase and MyDatabase_log. Our VERIFYONLY command becomes:
RESTORE VERIFYONLY FROM DISK = 'C:\folder\backupfile1.bak'
, DISK = 'C:\folder\backupfile2.bak'
WITH FILE = 1,
MOVE N'MyDatabase' TO N'C:\tmp\myDatabase.mdf',
MOVE N'MyDatabase_log' TO N'C:\tmp\myDatabase_log.ldf'
where we’ve specified we’re MOVE-ing our files to some dummy files in our temp directory, C:\tmp\. (During all the testing, I didn’t see any files appear in this temp directory, not even briefly, so I don’t know why this step is necessary really.) Running the above, we get:
The backup set on file 1 is valid.
Unsurprisingly, the time it takes to verify a backup is proportional to its size; for a database with two 30 GB .BAK files, it took 11 minutes on my very old PC.
NB: FILE refers to the ‘backup set file number’, which for all our .BAK files, was 1 — if I changed it to 2, I got the error message “Cannot find file ID 2 on device”.
Looping over all databases
Of course, rather than run these commands dozens of times, I’d like to automate as much as I can — so I wrote code that did the following:
- Got the full list of .BAK files using xp_dirtree
- Turned the list of files into a ‘nice’ temp table that I could loop over, one row per database.
- For each row in the temp table (i.e. database):
- Call RESTORE FILELISTONLY to get the logical names
- Using these, call RESTORE VERIFYONLY
Calling the RESTORE commands
I built my RESTORE FILELISTONLY code as a SQL string, EXEC-ed that, and stored the returned recordset in a table variable. See this very useful comment on stackoverflow for the table definition I used.
However, you can’t do exactly the same with RESTORE VERIFYONLY. You can EXEC the SQL string, as above, but if you try and store the results of the EXEC, you get:
Msg 3021, Level 16, State 0, Line 203
Cannot perform a backup or restore operation within a transaction.
Msg 3013, Level 16, State 1, Line 203
VERIFY DATABASE is terminating abnormally.
It looks like most people recommend putting the command in a TRY/CATCH block, something like the following:
BEGIN TRY RESTORE VERIFYONLY FROM DISK = @file1, DISK = @file2 WITH FILE = 1 , MOVE @Logical1 TO @tmp1 , MOVE @Logical2 TO @tmp2 END TRY BEGIN CATCH... error handling here...END CATCH
As you can see above, you can call RESTORE with @ variables, you don’t have to build a string and EXEC it — I just like to do that wherever possible, so I can PRINT the strings initially, therefore I know exactly what commands I’m going to be running.
SQL Server Full-Text Search
Posted by sqlpete in architecture, coding, systems on February 22, 2024
If you’re searching within text (string) data in SQL Server, the easiest method is to use the LIKE operator with the wildcard ‘%’ character, e.g.:
SELECT * FROM Customers WHERE FirstName LIKE 'Pete%'
will return every customer with the first name Pete or Peter, plus less common forenames like Peterjohn and Peterson. The search string (‘Pete%’) can contain multiple wildcards, and can be used to look for ranges or sets of characters. LIKE is quite powerful, although sadly not as powerful as a full-featured regular expression parser (something that Unix/Linux scripters will be very familiar with). More importantly, LIKE can’t always use column indexes that you think might be appropriate. In the above query, if FirstName was indexed, then that index would be used, but if the search string was e.g. ‘%illy’ (looking for ‘Milly’, ‘Gilly’, ‘Tilly’ or ‘Billy’), then it wouldn’t.
For a more high-powered approach to searching text within database tables, SQL Server has Full-Text Search. From that link:
Full-text queries perform linguistic searches against text data in full-text indexes by operating on words and phrases based on the rules of a particular language such as English or Japanese. Full-text queries can include simple words and phrases or multiple forms of a word or phrase.
I last used Full-Text Search a very long time ago — maybe in the days of SQL Server 7.0! — so I thought it was time to refresh my knowledge.
The dataset
I needed a reasonably large dataset for testing, so I downloaded the Free Company Data Product,
which is a “data snapshot containing basic company data of live companies on the register” at Companies House — basically, a CSV of every company currently incorporated here in the UK. The dataset I downloaded, dated 2024-02-07, was 452Mb zipped, 2.5Gb unzipped, and contains 5,499,110 rows and 55 columns.
After downloading and unzipping, I imported the CSV into SQL Server, then transferred it to a table with appropriate datatypes, also doing some tidying like removing NULL columns, and normalising out some categories to lookup tables. My main cleaned-up table is called cd.CompanyData (‘cd’ is the schema).
Not that it matters for what I’m doing here, but the data is pretty ropey in places; for example, the ‘previous name’ date fields unexpectedly switch from yyyy-mm-dd to dd/mm/yyyy. There are lots of duff postcodes, countries can have several slightly different names, and the address data is generally fairly low quality. For an important dataset from an official government source, I expected a lot better! If I was going to use this data in a professional setting, it’d take me a couple of days and a high-quality address cleaner to make it acceptable.
Creating the full-text index
I’m going to assume that you have the Full-Text Search component installed; it was literally a matter of ticking a checkbox on installation of SQL Server 2022 Developer edition. To check if it’s installed on your SQL Server instance, run:
SELECT FULLTEXTSERVICEPROPERTY('IsFullTextInstalled')
‘1’ means yes, ‘0’ means no.
Firstly, we have to create a Full-Text Catalog. Quote: “You have to create a full-text catalog before you can create a full-text index” — it’s merely a logical container for the full-text indexes we’ll create. In practice, it’s one line of SQL:
CREATE FULLTEXT CATALOG myFirstFullTextCatalog AS DEFAULT
Now we can create our first full-text index; we need three things: the table name (cd.CompanyData), the column we want to index (CompanyName) and the name of a unique key on that table (we can use our primary key, PK_cd_CompanyData):
CREATE FULLTEXT INDEX ON cd.CompanyData(CompanyName)
KEY INDEX PK_cd_CompanyData
WITH STOPLIST = SYSTEM
See CREATE FULLTEXT INDEX for more details. Note that we didn’t have to specify the catalog, as we’ve already declared a default. (Also, it doesn’t have to be a table we’re indexing, we can also add full-text indexes to indexed views.)
What does ‘STOPLIST = SYSTEM’ mean? The STOPLIST is a list of words that aren’t indexed, words like ‘and’, ‘but’, ‘in’, ‘is’. To see the SYSTEM list we’ve used here:
SELECT * FROM sys.fulltext_system_stopwords WHERE language_id = 1033
For me, it returns 154 rows, a list of words and some single characters. (NB: 1033 refers to English) You can curate your own STOPLISTs: Configure and Manage Stopwords and Stoplists for Full-Text Search
IMPORTANT: You can only add one full-text index to a table (or indexed view), but you can have multiple columns per index.
Using the index
You’ll notice that the CREATE FULLTEXT INDEX statement returns immediately; that doesn’t mean the index has been created that quickly, just that the indexing process has started. To keep an eye on the progress, I use the code from this stackoverflow answer. (For the index above, it took a couple of minutes on my old and severely under-powered Windows 10 PC; for multiple columns, it a took a bit longer.)
There are a number of ways to query the index: see Query with Full-Text Search, and Full-Text Search and Semantic Search Functions. Here, we’ll use the table function FREETEXTTABLE.
Let’s query the data, and look for all companies with the word ‘Tonkin’ in, order them by newest incorporated first:
;WITH cte_Search AS
(
SELECT
ft.[KEY]
,ft.[RANK]
FROM FREETEXTTABLE(cd.CompanyData, CompanyName, 'Tonkin') ft
)
SELECT
c.CompanyNumber
,c.CompanyName
,c.IncorporationDate
,ft.[RANK]
FROM cte_Search ft
JOIN cd.CompanyData c
ON c.CompanyNumber = ft.[KEY]
ORDER BY c.IncorporationDate DESC
There are 30 results, first 16 shown here:
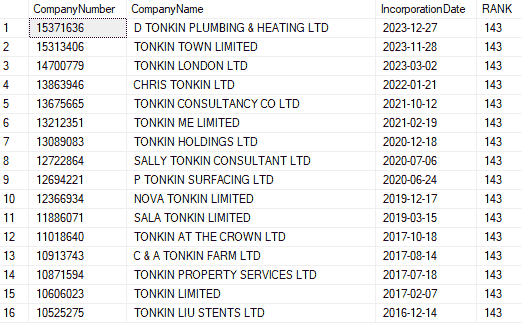
The results are returned within a fraction of a second; the equivalent query using LIKE took nearly 10 seconds.
Aside: Why have I written the query using a CTE, instead of a simple JOIN? When researching this post, I came across this from Brent Ozar: Why Full Text’s CONTAINS Queries Are So Slow
Apart from the increase in speed, the full-text index includes related words, e.g. if I change the query to search for ‘machine’, I get 2153 results where the company names contain ‘MACHINE’, ‘MACHINES’ and ‘MACHINING’. If I search for ‘move’, I get 2497 results where the company names contain ‘MOVE’, ‘MOVING’, ‘MOVED’, ‘MOVES’ and ‘MOVERS’.
But what’s going on with the RANK column? Excellent question, why are they all the same number? It’s to do with the query string we’re passing to FREETEXTTABLE; if it was more complicated, e.g. ‘move OR clean’, then I get eight different values for RANK: 9,13,17,24,30,40,41,43. This page, Limit search results with RANK, has some interesting tidbits.
Loads more to do…
I’ve only lightly scratched the surface here; I know from experience that Full-Text Search is something to seriously consider for a production system, but I’d like a few days of playing around with real data, and real use-cases, before committing. If you’ve an on-going need to locate pieces of text in a large table (e.g. customer search functionality), there are a few things that can be done without installing Full-Text Search:
- Ensuring current indexes are adequate, and actively being used by the SQL engine
- Indexing the first few characters of a string
- Splitting out words or other parts of strings into a separate table and indexing that
- Caching the most popular searches
- Storing or replicating the data to a Memory-Optimized Table
- Hashing words, pairs/triples of words, or full phrases, and indexing the hashes
- Enforcing other criteria to cut-down the search space, e.g. live customer? Applied this year?
and I’m sure I can come up with a few more, given time!
Inverting a matrix in SQL
As long ago as yesterday, I wrote:
I expect someone somewhere has converted pre-existing Fortran or C/C++ code into pure T-SQL. (The algorithm is fairly straightforward, so I doubt it’s that hard to do the conversion.)
Since writing those words, my brain has done nothing but nag at me, so guess what I did this morning?
NB: T-SQL is Microsoft’s own version of SQL — they’re close, but not exactly the same thing. I’ve left the title of the post as ‘SQL’ not ‘T-SQL’, because it should be straightforward to convert the guts of the code to generic SQL, if needed.
Picking an algorithm
No need to come up with my own matrix inversion algorithm, there are plenty to choose from; a google search led me to An Efficient and Simple Algorithm for Matrix Inversion by Farooq and Hamid, from 2010. Here’s their algorithm, written in C, from their paper:

It looks beautifully simple, and therefore, should be pretty easy to convert to SQL!
Conversion to SQL
Firstly, it’d be helpful to have a ‘matrix’ SQL type:
CREATE TYPE MatrixType AS TABLE
(
[row] INT NOT NULL
,[col] INT NOT NULL
,[value] FLOAT NOT NULL
,PRIMARY KEY CLUSTERED ([row],[col])
)
Using this type for my input parameter, here’s my conversion of Farooq and Hamid’s code (note that I’m using a function, not a stored procedure):
CREATE FUNCTION dbo.fn_InvertMatrix
(
@matrix MatrixType READONLY
)
RETURNS @result TABLE
(
[row] INT NOT NULL
,[col] INT NOT NULL
,[value] FLOAT NOT NULL
,PRIMARY KEY CLUSTERED ([row],[col])
)
AS
BEGIN
DECLARE @wkgMatrix MatrixType
INSERT @wkgMatrix([row],[col],[value])
SELECT [row],[col], [value]
FROM @matrix
DECLARE @size INT = (SELECT MAX([row]) FROM @wkgMatrix)
DECLARE @det FLOAT, @pivot FLOAT
,@p INT, @i INT, @j INT
,@mat_pj FLOAT, @mat_ip FLOAT
SET @det = 1.0
SET @p = 1
WHILE(@p <= @size)
BEGIN
SELECT @pivot = [value]
FROM @wkgMatrix
WHERE [row] = @p AND [col] = @p
SET @det = @det * @pivot
IF (ABS(@det) < 1e-5)
BEGIN
RETURN
END
UPDATE @wkgMatrix SET [value] = -[value]/@pivot WHERE [col] = @p
SET @i = 1
WHILE (@i <= @size)
BEGIN
IF (@i <> @p)
BEGIN
SELECT @mat_ip = [value] FROM @wkgMatrix WHERE [row] = @i AND [col] = @p
SET @j = 1
WHILE (@j <= @size)
BEGIN
IF (@j <> @p)
BEGIN
SELECT @mat_pj = [value] FROM @wkgMatrix WHERE [row] = @p AND [col] = @j
UPDATE @wkgMatrix SET [value] = [value] + (@mat_pj * @mat_ip)
WHERE [row] = @i AND [col] = @j
END
SET @j = @j + 1
END
END
SET @i = @i + 1
END
UPDATE @wkgMatrix SET [value] = [value] / @pivot WHERE [row] = @p
UPDATE @wkgMatrix SET [value] = 1.0/@pivot WHERE [row] = @p AND [col] = @p
SET @p = @p + 1
END
INSERT @result([row],[col],[value])
SELECT [row],[col], [value]
FROM @wkgMatrix
RETURN
END
Notes about this conversion:
- I’ve written the code as a function, it should be trivial to convert to a sproc if needed.
- I’ve removed a couple of loops from the original version; I think someone with time on their hands could make the code even smaller? Maybe a recursive CTE could work?
- There’s very little error-checking, e.g. I should at least check that the matrix is square. It’s not production-ready code — if it was, there’d be comments and headers.
So, does the code actually work? How can we test it? Let’s generate a random square matrix (from 2×2 up to 9×9), invert it, then check that when multiplied together, we get the identity matrix — then let’s do this thousands of times.
We’ll need a helpful SQL function to multiply two matrices together:
CREATE FUNCTION dbo.fn_MatrixMultiply
(
@m1 MatrixType READONLY
,@m2 MatrixType READONLY
)
RETURNS TABLE
AS
RETURN
(
SELECT
m1.[row]
,m2.[col]
,[value] = SUM(m1.[value] * m2.[value])
FROM @m1 m1
JOIN @m2 m2
ON m2.[row] = m1.[col]
GROUP BY m1.[row], m2.[col]
)
And we’re ready — let’s do a few thousand iterations, here’s my testing code:
DROP TABLE IF EXISTS #results
GO
CREATE TABLE #results
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED
,size INT NOT NULL
,[diag] FLOAT NOT NULL
,[offdiag] FLOAT NOT NULL
)
GO
SET NOCOUNT ON
DECLARE @Z INT = 1
DECLARE @m1 AS MatrixType
DECLARE @m2 AS MatrixType
DECLARE @mr AS MatrixType
DECLARE @size AS INT
WHILE(@Z <= 3000)
BEGIN
SET @size = 2 + ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT)) % 8 -- random from 2 to 9
DELETE FROM @m1
INSERT @m1([row],[col],[value])
SELECT x.r AS [row], y.c AS [col]
,[value] = CAST(CAST(CAST(NEWID() AS VARBINARY) AS INT) AS FLOAT)/1000000000.0
FROM (
VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)
) x(r)
CROSS JOIN (
VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)
) y(c)
WHERE x.r <= @size
AND y.c <= @size
DELETE FROM @m2
INSERT @m2([row],[col],[value])
SELECT [row],[col],[value] FROM dbo.fn_InvertMatrix(@m1)
DELETE FROM @mr
INSERT @mr([row],[col],[value])
SELECT [row],[col],[value] = ROUND([value],7)
FROM dbo.fn_MatrixMultiply(@m1, @m2)
INSERT #results(size,diag,offdiag)
SELECT
size = @size
,diag = (SELECT SUM(CASE WHEN [value] = 1.0 THEN 1 ELSE 0 END)
FROM @mr WHERE [row] = [col])
,offdiag = (SELECT SUM([value]) FROM @mr WHERE [row] <> [col])
SET @Z = @Z + 1
END
GO
If everything has worked as expected, then in every case, the size of the matrix will be the same as the sum of the diagonal elements, and the sum of the off-diagonal elements will be zero:
SELECT
N = COUNT(1)
,diag_ok = SUM(CASE WHEN size = diag THEN 1 ELSE 0 END)
,offdiag_ok = SUM(CASE WHEN offdiag = 0 THEN 1 ELSE 0 END)
FROM #results
GO
N diag_ok offdiag_ok
----------- ----------- -----------
3000 3000 3000
All good, looks like the code has worked perfectly!
Finally
Again, I’ve done nothing clever here, just piggy-backed off someone else’s good work. But now I’ve got my own ‘native’ SQL function to play with, no more messing about with SQLCLRs — quite the relief!
A few final points:
- Although I think the code works fine, I need to extensively compare the results with my SQLCLR function. For instance, my random matrices didn’t have any zeros in, and I restricted the range of the cell values, what happens with large values? Or a mixture of very big and very small values? What about much larger matrices?
- How fast is the code? It doesn’t matter for my use-case, but it might for other people’s. Maybe the SQLCLR function is much faster.
- Not all matrices are invertible, why didn’t I get any errors? This is answered here: Probability question: what are the odds that a random nxn matrix is invertible?
- Often, the determinant of the matrix is useful, I should work out a way to return that.
- Before converting to SQL, I converted the code to R, and now I really want to make an ‘arbitrary precision version of it, using the gmp library…
- It feels like I should start my own library of SQL functions to work with matrices — one day!
Inverting a matrix in SQL Server
Apologies in advance, this post is a little light on certain details. This is because (a) I don’t have time to write a big, exhaustive piece, that could easily be a 30-page document, and (b) the actual creation of the SQLCLR function in Visual Studio was more akin to witchcraft than coding (I’ll attempt to explain later on…) Also, there’s some waffle around credit risk, you can safely ignore it! 😉
My credit risk use-case
In credit risk, we always want to know what’s going to happen to the loans in our loan book. Will they eventually pay us back, or will they default? Clearly, this is very important information, and you can’t run a successful lending business without it.
Markov chains
One of the ways we predict what’s going to happen, is using a Markov Chain model. We generate a transition matrix from our data, and using matrix arithmetic, repeatedly multiply the matrix by itself to calculate what happens in the future. The Markov property is that the future states of a process only depend on the current state, not the past. (This is also referred to as ‘memoryless’.)
Here’s an example transition matrix that shows the statuses of loans last month, compared to this month.

(An old FD used to call this the ‘Was/Is’ matrix)
The numbers 0 to 6 refer to how many payments behind the customer is, D is default, and S is settled. For example, of the loans that were three payments down last month, 35% stayed three payments down; 4% returned to zero (‘up to date’), and 7% settled their account. None of them went straight to default. Note that the percentages add up to 100 row-wise, but not column-wise.
D (default) and S (settled) are called absorbing states — once you enter them, that’s it, you can’t come back. (In real life, this isn’t true, but we can ignore it here.)
Because of these absorbing states, our Markov chain is a special case, an Absorbing Markov Chain. Using the above transition matrix, we can calculate the long-term probabilities of settlement (repayment) or default for all our loans, given their current position.
To get these probabilities, we need to calculate 

E.g. an up-to-date loan currently has a 6% chance of defaulting. A loan that is 6 payments down only has a 25% chance of being repaid.
Inverting a matrix in Excel
Okay, couldn’t we just use Excel to do these calculations? Excel has an inbuilt function MINVERSE, see here for an example.
In the past, I’d done these calculations for a different loan book, using Excel, and the modelling had worked and told us what we needed to know. For the loan book I was working on now, I wanted to automate the calculations, over several different partitions of the data — for instance, if you have multiple products, then typically you’d need to do the calculations per product. Hence, the requirement to do everything within SQL Server.
Inverting a matrix from within SQL Server
I chose the title of this post carefully: we’re inverting a matrix using SQL Server, but the code isn’t written in SQL (T-SQL) itself. I expect someone somewhere has converted pre-existing Fortran or C/C++ code into pure T-SQL. (The algorithm is fairly straightforward, so I doubt it’s that hard to do the conversion.)
The two methods I’m proposing here both involve installing something to SQL Server itself, which admittedly may not be possible for everyone.
- Executing R code from within SQL Server, an example of running R code is given here. There are several libraries and functions dedicated to inverting matrices; solve from the base installation and inv from the matlib package are two of the most popular.
- Creating a SQLCLR function using C#
It’s the second one we’ll look at for the remainder of this post.
Creating an assembly using SQLCLR
Below is the exact (not terribly well-written) C# code that I used to create an assembly in Visual Studio, that I could then publish to my instance of SQL Server, and then use the function MatrixInvert as I would any other SQL function call.
using System; using System.Data; using System.Linq; using System.Data.SqlClient; using System.Data.SqlTypes; using System.IO; using System.Text; public partial class UserDefinedFunctions { [Microsoft.SqlServer.Server.SqlFunction] public static SqlString MatrixInvert(SqlString matrixAsString) { string[][] strMatrix = (matrixAsString.ToString()).Split(';').Select(x => x.Split(',')).ToArray(); int matrixX = strMatrix.Length; for (int i = 0; i < matrixX; i++) { if (strMatrix[i].Length != matrixX) { throw new Exception("Matrix not square NxN"); } } int matrixSize = matrixX; double[][] matrix = new double[matrixSize][]; for (int i = 0; i < matrixSize; i++) { matrix[i] = new double[matrixSize]; } for (int i = 0; i < matrixSize; i++) { for (int j = 0; j < matrixSize; j++) matrix[i][j] = Convert.ToDouble(strMatrix[i][j]); } double[][] inverseMatrix = MatrixInverse(matrix); double[][] identityMatrix = MatrixIdentity(matrixSize); double[][] product = MatrixProduct(matrix, inverseMatrix); String result = null; Boolean matrixAreEqual = MatrixAreEqual(product, identityMatrix, 1.0E-8); if (matrixAreEqual == true) { for (int i = 0; i < matrixSize; i++) { for (int j = 0; j < matrixSize; j++) { result += inverseMatrix[i][j].ToString(); if (j < (matrixSize - 1)) result += ','; } if (i < (matrixSize - 1)) result += ';'; } } else { result = null; } return (result); }// here: add code from https://jamesmccaffrey.wordpress.com/2015/03/06/inverting-a-matrix-using-c/}
As you’ll no doubt spot, the code is incomplete — see the final comment. Because it was convenient, I used the C# code from James D. McCaffrey’s blog post Inverting a Matrix using C#. (I don’t want to reproduce his code here, you’ll have to grab it for yourself – but you literally don’t have to do anything to it, just copy and paste.) If this code hadn’t been available, I was going to adapt the code in my venerable copy of ‘Numerical Recipes in C’ (current website here).
Other points to note:
- My function MatrixInvert calls the functions MatrixInverse, MatrixIdentity, MatrixProduct and MatrixAreEqual from James D. McCaffrey’s code. My function is not much more than a wrapper around the clever stuff.
- The figures are passed to the function as a single delimited string (comma / semi-colon), and returned similarly. There’s undoubtedly a better way of doing this, but it works.
- The code checks that the original matrix multiplied by its inverse equals the identity, to some tolerance level, and returns null if this isn’t the case.
- There could be more error-checking — there could always be more error-checking!
But how did I get this code into SQL Server? So here come the excuses…
The last time I wrote a SQLCLR (maybe 2 years ago?), I downloaded the latest Visual Studio, created a ‘SQL Server Database Project’, wrote my code, hit ‘Publish’, entered the database details, and it sorta just worked. (Least, that’s how I remember it.) While writing this post, I followed the same path… and it took ages, with a ton of googling throughout. Finally, I got it working again, but it wasn’t a pleasant experience. In the end, I had to manually paste in SQL similar to the following:

and set/unset some configuration values:
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'clr strict security', 0;
RECONFIGURE;
EXEC sp_configure 'clr enabled', 1;
RECONFIGURE;
I’m sure it wasn’t this hard last time!
At this point, the SQL function dbo.MatrixInvert is available for me to use. To test it out, let’s take an integer matrix that has an inverse that only contains integers; I got my example from the blog post “Random Integer Matrices With Inverses That Are Also Integer Matrices. The code below builds up our input matrix (as a string), calls the function, then parses the string that’s returned.
DECLARE @myMatrix VARCHAR(MAX)
SET @myMatrix = '9,21,23,8,18,7,12,7;
8,13,15,5,10,5,9,6;
0,13,11,2,13,1,3,0;
13,11,16,13,6,11,13,10;
11,21,23,7,17,7,13,8;
10,8,12,9,4,8,10,8;
11,16,19,7,12,7,12,8;
6,12,14,6,10,5,8,5'
DECLARE @invertedMatrix VARCHAR(MAX)
SELECT @invertedMatrix = dbo.MatrixInvert(@myMatrix)
SELECT
[row]
,[col] = ROW_NUMBER() OVER
(PARTITION BY [row] ORDER BY GETDATE())
,ROUND(CAST(s.[value] AS FLOAT), 2) AS [value]
FROM (
SELECT [row] = ROW_NUMBER() OVER (ORDER BY GETDATE())
,[value] AS rowStr
FROM STRING_SPLIT(@invertedMatrix, ';')
) x
CROSS APPLY STRING_SPLIT(x.rowStr, ',') s
ORDER BY [row],[col]
GO
The result set has 64 rows, and starts like this:

All good, it matches the inverse from the original blog post!
Of course, you can pass floats into the function, I used this integer matrix because it looked ‘clean’.
One thing I can’t let pass without comment: why the heck have I used ORDER BY GETDATE() in my ROW_NUMBER window function? Because, somewhat unbelievably, SQL Server’s STRING_SPLIT function doesn’t return an ordinal associated with the position, so I’m trying to force it to behave repeatably; see Row numbers with nondeterministic order for more information. In a production setting, I’d probably use my own hand-rolled function to split strings.
An admission of failure
Finally, an admission of failure: not the code, that all worked perfectly, I was able to calculate my inverse matrices and ‘final state’ probabilities. Except… the models didn’t work. I’d started off looking at older data, seeing if I could replicate the state of loans a few years down the line, and I couldn’t get it to work. I split the data into products, into cohorts, by customer attributes, started looking at second and higher order Markov chains (where the ‘present’ doesn’t just depend on the immediate past, but two, three, etc. steps ago), and nothing worked. In the end, I had to admit defeat. A few months later, I was talking to a Financial Director about my lack of success on this particular loan book — and he said he wasn’t surprised, that in his experience, this sort of modelling didn’t work on some shorter-term financial products. That made me feel somewhat better, but I still want to know what the ‘correct’ model was!
Postscript: Several years later, I was chatting with an agent who’d worked in the operations department, who told me that there was a manual component to the status changes (the statuses weren’t the traditional ‘0-6 payments down’) that I wasn’t aware of when I did the original modelling. I can’t put all the blame on this, but it did go some way to explaining the lack of consistency I was seeing in the data, and I should’ve pushed harder to understand it at the time.
A quick review of some sketchy SQL
For a brief time, I have access to some database code from a defunct lending company, that I worked for in the past. While rootling through the code for another reason, I came across a small sproc that I thought it might be interesting to take a look at in some detail, to point out issues with the code – some minor, some less so.
Actually, the sproc (which generated data for a report) had some additional parts to it, but those were almost identical with respect to the issues we’re concerned with here, so we’ll just concentrate on this first part.
Firstly, a caveat: the person who wrote the code was not a native SQL coder, they were a C# developer. It’s been common for many years, especially in smaller companies, for devs to be responsible for most, if not all, of the SQL that gets written. I am absolutely not picking on this coder, and there are certainly more egregious examples I could have used, written by more senior folk! I chose this code because it nicely demonstrates one of my least-favourite SQL patterns, which really comes down to ‘trying to do too much at once, at the expense of performance issues and readability’.
The code

The image above shows a truncated view of the code, click on it to see the full width.
For obvious reasons, I’ve removed the header, which contained the sproc name, the coder’s first name and a too-brief description of the code. Ideally, all sprocs should have headers with lots of information in them, including a change-log (if there’s no source control available).
It doesn’t really matter what the tables and columns are, we’re talking more about the ‘shape’ of the code, how the query is constructed.
The issues
It’s not all bad, let’s start off with the good points.
The good points
- The code uses temp tables for the right reasons. They may not have made the most of it (no indexes, see below), but if a query is complicated enough, I will use temp tables extensively. It helps greatly with readability, and almost always, with performance too.
- The tables are aliased. (i.e. BPM, PST, PT, T) Ok, I prefer lower-case aliases, but that’s minor. Better that than nothing; it’s clear here which table contains which column. I’ve seen code where the entire table name is used as the alias, and it was unreadable. (They missed out the alias on the final ‘Order By’, a small mistake.)
Minor issues
- Magic numbers: Values of ProductIDs are given without any explanation/comment; yes, if you know the codebase, this isn’t a problem, but if you’re new, it’d be helpful to spell out what these values mean.
- Temp table has ‘Temp’ in the name, not really necessary(*)
- There’s no DROP TABLE IF EXISTS statement before CREATE TABLE, which would help with debugging — not strictly necessary, just helpful.
(*) I like my temp tables to not have the same name as ‘real’ tables, just in case a DROP TABLE statement goes awry! I guess putting ‘Temp’ in front of the table name makes this a non-issue.
Less major issues
- Formatting in general; it’s inconsistent and hard to read, e.g. the code extends out past column 300 (and even further in the full code)
- Spelling: It’s ‘instalment’ not ‘installment’; spelling is an issue throughout the entire codebase, they were far from the only culprit
- Date range: I much prefer my date ranges to be ‘right-open’, i.e. [CreatedDate] >= @fromDate AND [CreatedDate] < @toDate (not <=), to make things explicit.
- The temp table doesn’t have a primary key or any indexes; this is one of the main reasons for using temp tables in sprocs, to put your own indexes on that will benefit your individual query
- What’s the point of the Order by LoanDuration clause?
- Lack of comments: There are no useful comments anywhere in the sproc!
More major issues
- They didn’t really understand how the ‘CASE’ statement works
- At the bottom of the query, they’re GROUPing by too many things (!a big ‘code smell’!), which is a consequence of doing the COUNT() in the main query — this is not a nicely written query, it can be greatly improved
Doing too much at once
It’s the last of these major issues I want to concentrate on, as it’s something I see constantly: the coder is trying to do too many things at once, which makes the code impenetrable, hard to debug, and greatly increases the likelihood of the results being wrong.
The intention of the coder was that #Temploandetails had one row per loan (each row of BorrowerProductMapping is an instance of an application/loan). Hence, if I was going to re-write the code, I’d put an appropriate primary key on the temp table, and use one of the following patterns:
SELECT <fields>
FROM [dbo].[BorrowerProductMapping] bpm
OUTER APPLY (
SELECT
NumTerms = COUNT(1)
FROM [dbo].[Terms] ti
WHERE ti.CustomerProductID = bpm.CustomerProductID
GROUP BY ti.CustomerProductID
) t
WHERE <conditions>...
or
SELECT <fields>
FROM [dbo].[BorrowerProductMapping] bpm
LEFT JOIN (
SELECT
ti.CustomerProductID
NumTerms = COUNT(1)
FROM [dbo].[Terms] ti
GROUP BY ti.CustomerProductID
) t
ON t.CustomerProductID = bpm.CustomerProductID
WHERE <conditions>...
The intent is much clearer, doesn’t involve aggregation over everything, and therefore doesn’t involve a large unnecessary GROUP BY clause.
OUTER APPLY vs LEFT JOIN
Note that the two constructs above aren’t identical, they’ll perform differently depending on how much data is in the Terms table. The OUTER APPLY version may do a scan per row of the outer table, which in some circumstances could be expensive. There are many forum and blog posts about this, just google ‘OUTER APPLY versus LEFT JOIN’.
Interesting aside: when writing the code above, I idly left off the ‘GROUP BY’ inside the OUTER APPLY; on the face of it, it’s unnecessary, because we’re already restricting to a single CustomerProductID. However, I did some testing on a limited dataset, and including the GROUP BY results in (a) a different query plan; (b) much better performance and faster execution; and (c) different output — NumTerms is NULL for non-matching IDs if we use GROUP BY, but zero if we don’t use it. I think I understand why the difference exists, but I can’t say it enough: test your code!
What would I do?
I’d test three options. The first two as above, and for a third, I’d initially create a ‘Scope’ temp table with the CustomerProductIDs from the required date range, and use the Scope table to join to the Terms; I can see that the CreatedDate was nicely indexed on BorrowerProductMapping, so the data for the Scope table would come straight from the index, no need to touch the main table at all! Also, for this particular sproc, I could then re-use the Scope table in the other very similar queries (not shown here). I did some testing on small date ranges, and this third option marginally improved performance. But I would not assume that the performance would be automatically improved for large date ranges too — plus there’s also the consideration of the balance to be had between having more code, and marginal performance gains.
The Big Question
Okay, so the code could be improved, does that matter? If it works, it’s not something that need concern us too much, right?
Well, actually, the code is wrong. Not massively, but the complete sproc returns a data set with duplicate rows; maybe these were filtered out by the report, I don’t know.
The cause of the dupes is almost certainly down to writing queries with multiple joins, left joins and aggregations all mixed together in one big query. With a bit more thought and care, it wouldn’t have happened. Even worse is that they clearly didn’t run enough (any?) tests on the output! When writing sprocs like this, you should always pipe the output into a temp table, and check that the data is exactly what you’re expecting (in this case, one row per loan). Ultimately, that’s the worst offense here — you should always test your code!

Recent Comments